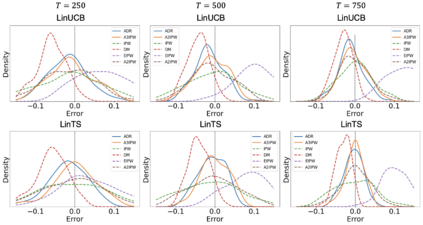
Adaptive experiments, including efficient average treatment effect estimation and multi-armed bandit algorithms, have garnered attention in various applications, such as social experiments, clinical trials, and online advertisement optimization. This paper considers estimating the mean outcome of an action from samples obtained in adaptive experiments. In causal inference, the mean outcome of an action has a crucial role, and the estimation is an essential task, where the average treatment effect estimation and off-policy value estimation are its variants. In adaptive experiments, the probability of choosing an action (logging policy) is allowed to be sequentially updated based on past observations. Due to this logging policy depending on the past observations, the samples are often not independent and identically distributed (i.i.d.), making developing an asymptotically normal estimator difficult. A typical approach for this problem is to assume that the logging policy converges in a time-invariant function. However, this assumption is restrictive in various applications, such as when the logging policy fluctuates or becomes zero at some periods. To mitigate this limitation, we propose another assumption that the average logging policy converges to a time-invariant function and show the doubly robust (DR) estimator's asymptotic normality. Under the assumption, the logging policy itself can fluctuate or be zero for some actions. We also show the empirical properties by simulations.
翻译:适应性实验,包括高效平均治疗效果估计和多臂强盗算法,在社会实验、临床试验和在线广告优化等各种应用中引起注意。本文件考虑从适应性实验中获取的样本中估计行动的平均值结果。在因果推断中,一项行动的平均值结果具有关键作用,而这一估计是一项基本任务,因为平均治疗效果估计和政策外值估计是其变量。在适应性实验中,选择一项行动(博客政策)的概率可以根据过去观察结果进行顺序更新。由于这一伐木政策取决于以往的观察结果,样本往往不独立,而且分布相同(i.d.),因此很难开发出一个无症状的正常估计结果。 这一问题的一个典型办法是假设伐木政策在时间变异功能中趋于一致。 但是,这一假设在各种应用中是限制性的,例如伐木政策波动或在某些时期变为零。为了减轻这一限制,我们建议另一种假设,即平均伐木政策政策与时间变化假设一致,(i.d.d.d.),使一个无症状的假设本身成为稳健的模拟。