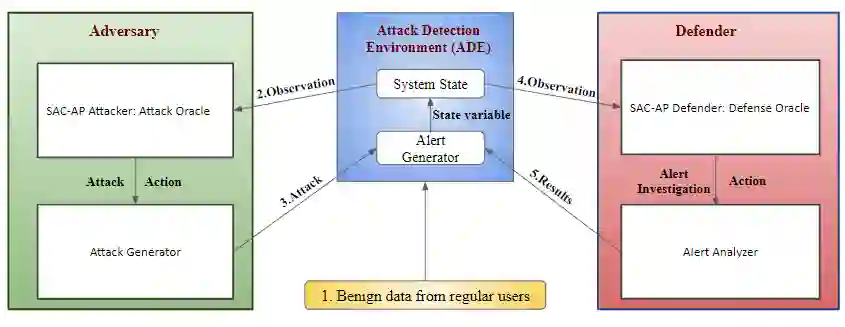
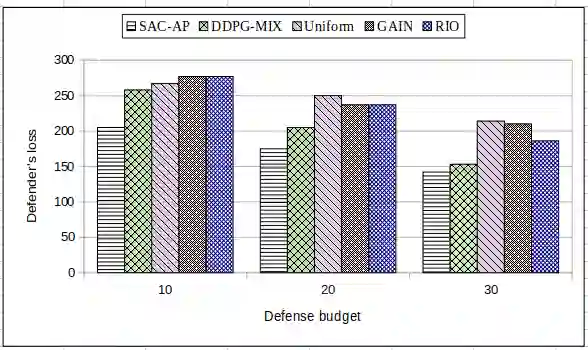
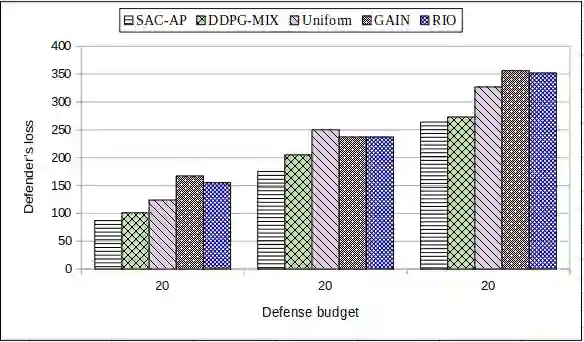
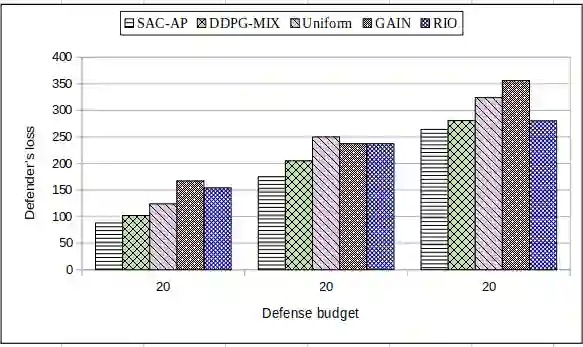
Intrusion detection systems (IDS) generate a large number of false alerts which makes it difficult to inspect true positives. Hence, alert prioritization plays a crucial role in deciding which alerts to investigate from an enormous number of alerts that are generated by IDS. Recently, deep reinforcement learning (DRL) based deep deterministic policy gradient (DDPG) off-policy method has shown to achieve better results for alert prioritization as compared to other state-of-the-art methods. However, DDPG is prone to the problem of overfitting. Additionally, it also has a poor exploration capability and hence it is not suitable for problems with a stochastic environment. To address these limitations, we present a soft actor-critic based DRL algorithm for alert prioritization (SAC-AP), an off-policy method, based on the maximum entropy reinforcement learning framework that aims to maximize the expected reward while also maximizing the entropy. Further, the interaction between an adversary and a defender is modeled as a zero-sum game and a double oracle framework is utilized to obtain the approximate mixed strategy Nash equilibrium (MSNE). SAC-AP finds robust alert investigation policies and computes pure strategy best response against opponent's mixed strategy. We present the overall design of SAC-AP and evaluate its performance as compared to other state-of-the art alert prioritization methods. We consider defender's loss, i.e., the defender's inability to investigate the alerts that are triggered due to attacks, as the performance metric. Our results show that SAC-AP achieves up to 30% decrease in defender's loss as compared to the DDPG based alert prioritization method and hence provides better protection against intrusions. Moreover, the benefits are even higher when SAC-AP is compared to other traditional alert prioritization methods including Uniform, GAIN, RIO and Suricata.
翻译:入侵探测系统(IDS)产生大量虚假警报,使得难以检查真实的正数。 因此, 警戒优先排序在决定哪些警报用于调查由IDS产生的大量警报中发挥着关键作用。 最近, 深度强化学习(DRL)基于深度确定性政策梯度(DDPG)的离政策方法显示,与其他最先进方法相比,在优先排序预警方面取得了更好的结果。 但是, DDPG容易出现过度配置的问题。 此外, DDPG也缺乏探索能力,因此不适合处理与随机环境有关的问题。 为了应对这些限制,我们展示了基于软的动作批评性DRL(SAC-AP)算法,以提醒优先排序(SAC-AP)算出一个基于最大增压性强化学习框架,目的是最大限度地增加预期的奖励,同时尽量扩大增压。 此外, 对手和捍卫者之间的交互互动模式是零和双重或两极分框架,用来获得接近的混合战略(MSNEAR-C)升级(MS-AC), 以SARC-SRAS-S-resent requist rest reforst reforst reforst reforst reforst reforst reforst sess sess refervation sess sess sess sal sal sal sal resmal ress) resmal ress ress supal deviewtal ress s reviews to ress sal ress supal sal ress sal lats。 我们算。 我们算起算。