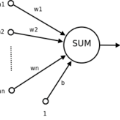
Artificial neural networks have advanced due to scaling dimensions, but conventional computing faces inefficiency due to the von Neumann bottleneck. In-memory computation architectures, like memristors, offer promise but face challenges due to hardware non-idealities. This work proposes and experimentally demonstrates layer ensemble averaging, a technique to map pre-trained neural network solutions from software to defective hardware crossbars of emerging memory devices and reliably attain near-software performance on inference. The approach is investigated using a custom 20,000-device hardware prototyping platform on a continual learning problem where a network must learn new tasks without catastrophically forgetting previously learned information. Results demonstrate that by trading off the number of devices required for layer mapping, layer ensemble averaging can reliably boost defective memristive network performance up to the software baseline. For the investigated problem, the average multi-task classification accuracy improves from 61 % to 72 % (< 1 % of software baseline) using the proposed approach.
翻译:暂无翻译