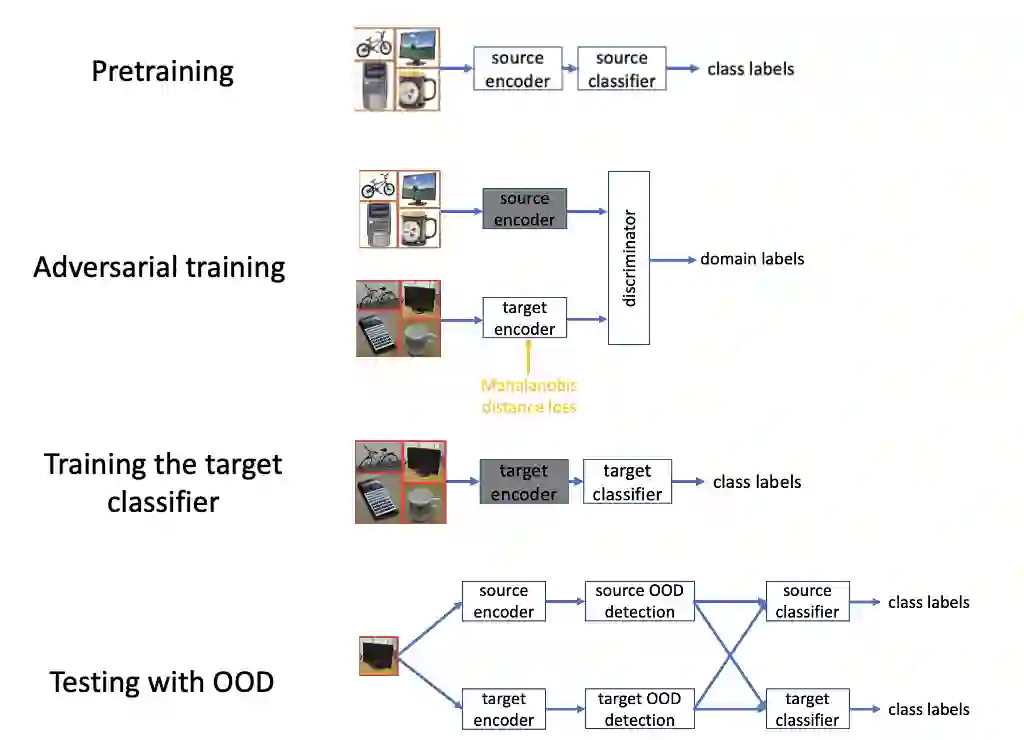
In smart computing, the labels of training samples for a specific task are not always abundant. However, the labels of samples in a relevant but different dataset are available. As a result, researchers have relied on unsupervised domain adaptation to leverage the labels in a dataset (the source domain) to perform better classification in a different, unlabeled dataset (target domain). Existing non-generative adversarial solutions for UDA aim at achieving domain confusion through adversarial training. The ideal scenario is that perfect domain confusion is achieved, but this is not guaranteed to be true. To further enforce domain confusion on top of the adversarial training, we propose a novel UDA algorithm, \textit{E-ADDA}, which uses both a novel variation of the Mahalanobis distance loss and an out-of-distribution detection subroutine. The Mahalanobis distance loss minimizes the distribution-wise distance between the encoded target samples and the distribution of the source domain, thus enforcing additional domain confusion on top of adversarial training. Then, the OOD subroutine further eliminates samples on which the domain confusion is unsuccessful. We have performed extensive and comprehensive evaluations of E-ADDA in the acoustic and computer vision modalities. In the acoustic modality, E-ADDA outperforms several state-of-the-art UDA algorithms by up to 29.8%, measured in the f1 score. In the computer vision modality, the evaluation results suggest that we achieve new state-of-the-art performance on popular UDA benchmarks such as Office-31 and Office-Home, outperforming the second best-performing algorithms by up to 17.9%.
翻译:在智能计算中,特定任务训练样本的标签并不总是充足的。然而,相关但不同的数据集中样本的标签是可获得的。因此,研究人员依赖于无监督域自适应来利用一个数据集(源域)中的标签,以便在不同的、未标记的数据集(目标域)中进行更好的分类。现有的无生成对抗解决方案的UDA旨在通过对抗性训练实现领域混淆。理想情况下,完美的领域混淆是可以实现的,但不一定能够实现。为了在对抗性训练之上进一步强化领域混淆,我们提出了一种新的UDA算法E-ADDA,它既使用了一种新颖的马氏距离损失函数的变体,又使用了一种超出分布检测的子程序。马氏距离损失最小化编码目标样本和源域分布之间的分布距离,从而在对抗性训练之上强化附加的领域混淆。然后,OOD子程序进一步消除领域混淆失败的样本。我们在声学和计算机视觉模态方面进行了广泛全面的E-ADDA评估。在声学模态中,E-ADDA比多种最先进的UDA算法表现出最高29.8%的f1得分。在计算机视觉模态中,评估结果表明,我们在流行的UDA基准测试,如Office-31和Office-Home上实现了新的最先进性能,比次优表现算法表现高出了最高17.9%。