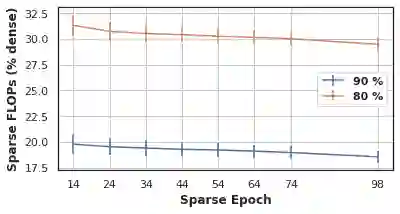
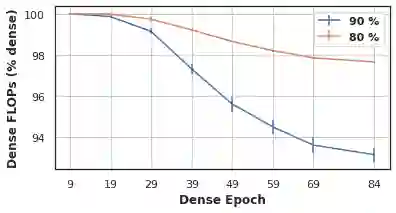
The increasing computational requirements of deep neural networks (DNNs) have led to significant interest in obtaining DNN models that are sparse, yet accurate. Recent work has investigated the even harder case of sparse training, where the DNN weights are, for as much as possible, already sparse to reduce computational costs during training. Existing sparse training methods are mainly empirical and often have lower accuracy relative to the dense baseline. In this paper, we present a general approach called Alternating Compressed/DeCompressed (AC/DC) training of DNNs, demonstrate convergence for a variant of the algorithm, and show that AC/DC outperforms existing sparse training methods in accuracy at similar computational budgets; at high sparsity levels, AC/DC even outperforms existing methods that rely on accurate pre-trained dense models. An important property of AC/DC is that it allows co-training of dense and sparse models, yielding accurate sparse-dense model pairs at the end of the training process. This is useful in practice, where compressed variants may be desirable for deployment in resource-constrained settings without re-doing the entire training flow, and also provides us with insights into the accuracy gap between dense and compressed models.
翻译:深神经网络(DNN)的计算要求不断提高,导致人们对获得分散但准确的DNN模型的兴趣极大。最近的工作调查了更困难的少许培训案例,因为DNN的重量在培训期间尽可能少,以降低计算成本。现有的少许培训方法主要是经验性的,往往比密集基线的精确度低。在本文中,我们提出了一个一般方法,称为“交替压缩/压缩(AC/DC)” DNN培训,表明对一种变式算法的趋同,并表明AC/DC在类似计算预算的精确度方面比现有的少许培训方法要好;在高宽度水平上,AC/DC甚至比现有方法要差,而后者依赖精确的事先培训密度模型。AC/DC的一个重要特征是,它允许对密度和稀薄的模型进行联合培训,在培训过程结束时产生精确的稀薄模型。这在实践上是有用的,在资源紧凑的环境下,压缩的变异体可能适合在资源紧凑环境中部署,而没有再精确度地提供我们整个模型的精确度。