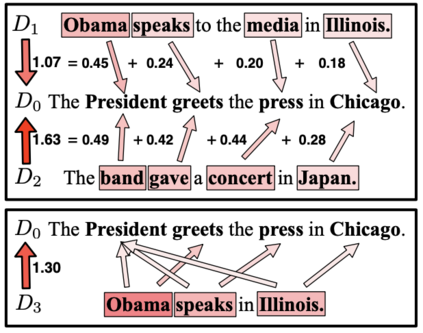
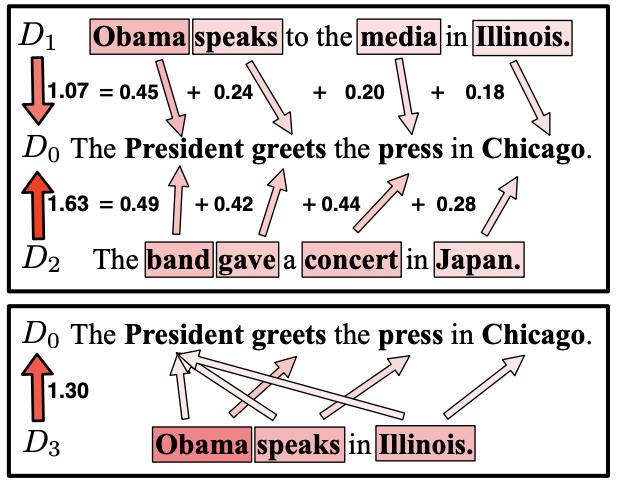
Despite the increasing popularity of NLP in the humanities and social sciences, advances in model performance and complexity have been accompanied by concerns about interpretability and explanatory power for sociocultural analysis. One popular model that balances complexity and legibility is Word Mover's Distance (WMD). Ostensibly adapted for its interpretability, WMD has nonetheless been used and further developed in ways which frequently discard its most interpretable aspect: namely, the word-level distances required for translating a set of words into another set of words. To address this apparent gap, we introduce WMDecompose: a model and Python library that 1) decomposes document-level distances into their constituent word-level distances, and 2) subsequently clusters words to induce thematic elements, such that useful lexical information is retained and summarized for analysis. To illustrate its potential in a social scientific context, we apply it to a longitudinal social media corpus to explore the interrelationship between conspiracy theories and conservative American discourses. Finally, because of the full WMD model's high time-complexity, we additionally suggest a method of sampling document pairs from large datasets in a reproducible way, with tight bounds that prevent extrapolation of unreliable results due to poor sampling practices.
翻译:尽管在人文科学和社会科学中国家实验室越来越受欢迎,但模型性表现和复杂性的进步伴随着对社会文化分析的解释性和解释力的关切。一个兼顾复杂性和可辨度的流行模式是“Word Moler”距离(World Moler's Learth) 。尽管可以合理调整,但大规模毁灭性武器的使用和进一步发展方式经常抛弃其最易解的方面:即将一套词转换成另一套词所需的字级距离。为了解决这一明显差距,我们引入了大规模毁灭性武器:一个模型和Python图书馆,它1)将文件水平的距离分解成其构成的字级距离,2)随后将一些文字分组,以诱导出主题要素,例如有用的词汇信息被保留和总结以供分析。为了在社会科学背景下说明其潜力,我们将其应用于一个纵向的社会媒体系统,以探讨阴谋理论和美国保守言论之间的相互关系。最后,由于整个大规模毁灭性武器模型的时间性很高,我们建议采用一种方法,从大型数据集取样,以可追溯性强的方式从大量数据集成。