
Due to the wide applications in recommendation systems, multi-class label prediction and deep learning, the Maximum Inner Product (MIP) search problem has received extensive attention in recent years. Faced with large-scale datasets containing high-dimensional feature vectors, the state-of-the-art LSH-based methods usually require a large number of hash tables or long hash codes to ensure the searching quality, which takes up lots of index space and causes excessive disk page accesses. In this paper, we relax the guarantee of accuracy for efficiency and propose an efficient method for c-Approximate Maximum Inner Product (c-AMIP) search with a lightweight iDistance index. We project high-dimensional points to low-dimensional ones via 2-stable random projections and derive probability-guaranteed searching conditions, by which the c-AMIP results can be guaranteed in accuracy with arbitrary probabilities. To further improve the efficiency, we propose Quick-Probe for quickly determining the searching bound satisfying the derived condition in advance, avoiding the inefficient incremental searching process. Extensive experimental evaluations on four real datasets demonstrate that our method requires less pre-processing cost including index size and pre-processing time. In addition, compared to the state-of-the-art benchmark methods, it provides superior results on searching quality in terms of overall ratio and recall, and efficiency in terms of page access and running time.
翻译:由于建议系统应用广泛,多级标签预测和深层次学习,最大内产物搜索问题近年来受到广泛关注。面对包含高维特性矢量的大型数据集、最先进的LSH方法通常需要大量的散列表或长散列码才能确保搜索质量,这需要大量索引空间,并造成过多的磁盘访问。在本文件中,我们放松对效率准确性的保证,提出一种高效的C-近似最大内产物搜索方法,并采用轻度的IDV指数。我们通过2级随机预测和概率保证搜索条件预测低维值点,从而通常需要大量的散列表或长散列码来确保搜索质量,从而可以任意地保证准确性,从而使用大量索引空间,并造成过多的磁盘访问访问。我们建议“快速方案”,以便快速确定事先的搜索是否满足既定条件,避免效率不高的增量搜索进程。我们对4个实际的IDD值进行了广泛的实验性评估,通过2级随机预测和得出概率保证的搜索条件,从而保证c-AMIP结果的准确性,从而确定前处理前的升级处理成本。我们的方法要求比前的升级的升级的升级的升级。



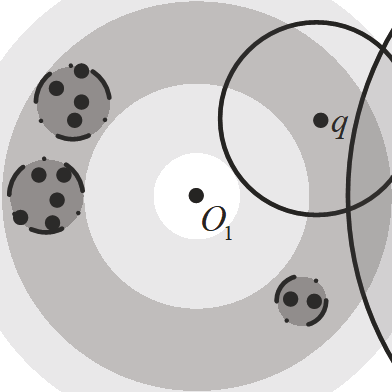

相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


