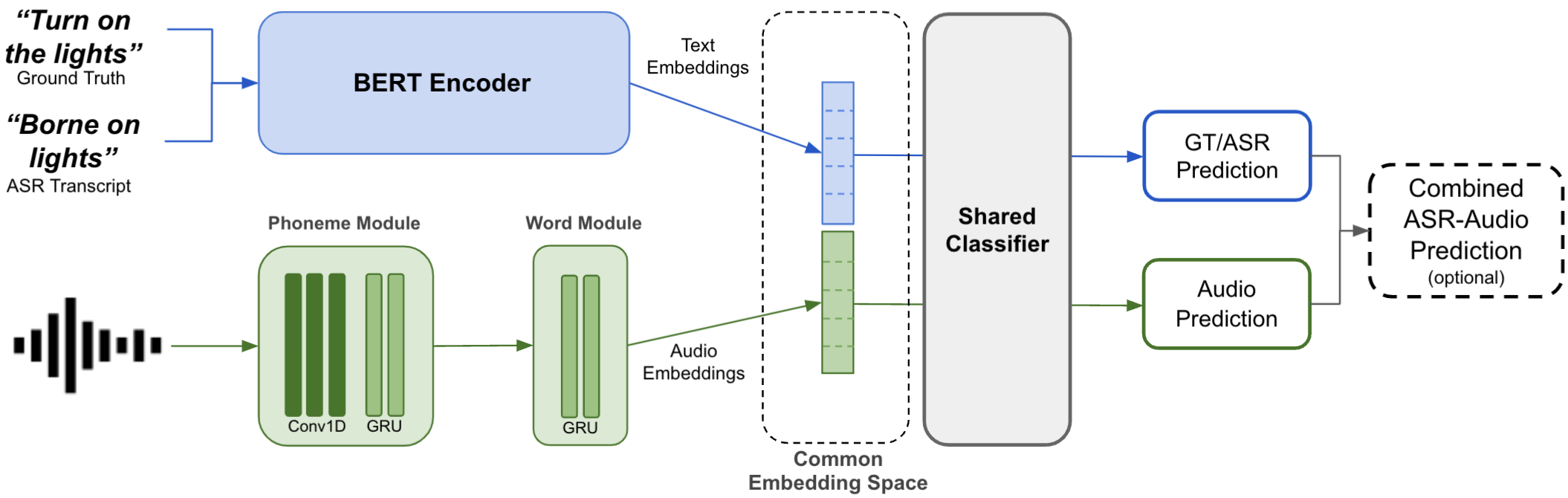
A major focus of recent research in spoken language understanding (SLU) has been on the end-to-end approach where a single model can predict intents directly from speech inputs without intermediate transcripts. However, this approach presents some challenges. First, since speech can be considered as personally identifiable information, in some cases only automatic speech recognition (ASR) transcripts are accessible. Second, intent-labeled speech data is scarce. To address the first challenge, we propose a novel system that can predict intents from flexible types of inputs: speech, ASR transcripts, or both. We demonstrate strong performance for either modality separately, and when both speech and ASR transcripts are available, through system combination, we achieve better results than using a single input modality. To address the second challenge, we leverage a semantically robust pre-trained BERT model and adopt a cross-modal system that co-trains text embeddings and acoustic embeddings in a shared latent space. We further enhance this system by utilizing an acoustic module pre-trained on LibriSpeech and domain-adapting the text module on our target datasets. Our experiments show significant advantages for these pre-training and fine-tuning strategies, resulting in a system that achieves competitive intent-classification performance on Snips SLU and Fluent Speech Commands datasets.
翻译:最近对口语理解(SLU)研究的一个主要重点是端对端方法,即单一模型可以直接预测来自语言投入的意向,而没有中间记录誊本,但这一方法提出了一些挑战。首先,由于言论可以被视为个人可识别的信息,在某些情况下只能获得自动语音识别(ASR)记录誊本。第二,用意标标的语音数据很少。为了应对第一个挑战,我们提议了一个新系统,可以预测来自灵活投入类型的意向:演讲、ASR笔录或两者兼而有之。我们通过系统组合,在两种模式中都可直接预测语言投入的意图时,显示我们取得优于单一输入模式的成绩。为了应对第二个挑战,我们利用经过预先培训的BERT模型,并采用一个双调系统,在共同的潜伏空间中共同进行文字嵌入和声源嵌入。我们通过在LibriSpeech和域调整我们目标数据集的文本模块上,我们展示了很强的功能,我们实验展示了这些前期测试和后级指令战略的优势。