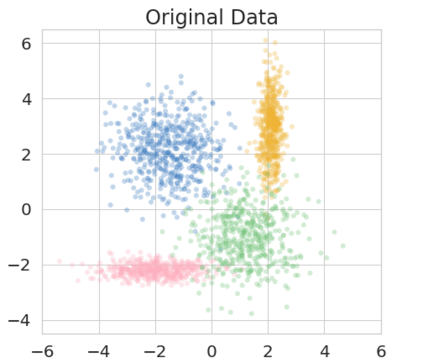
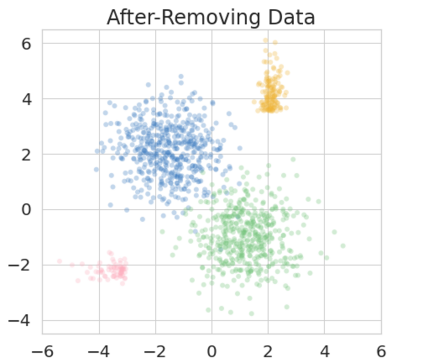
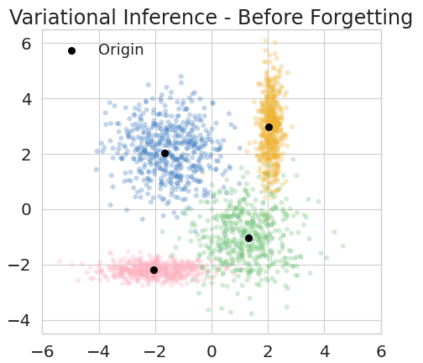
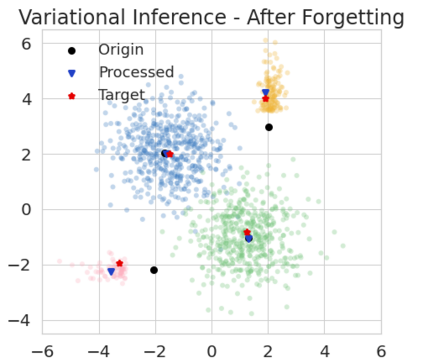
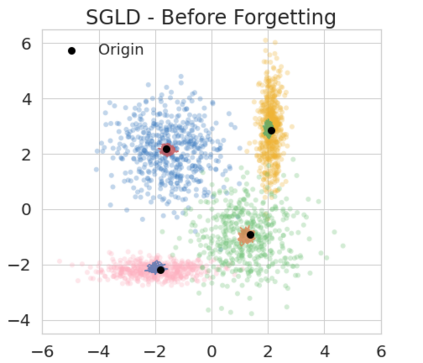
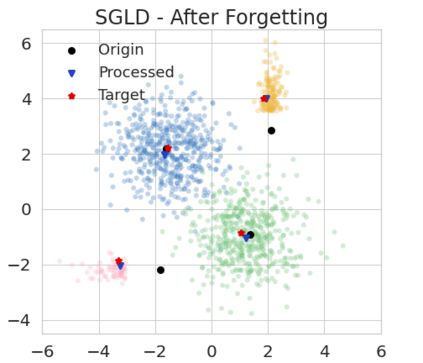
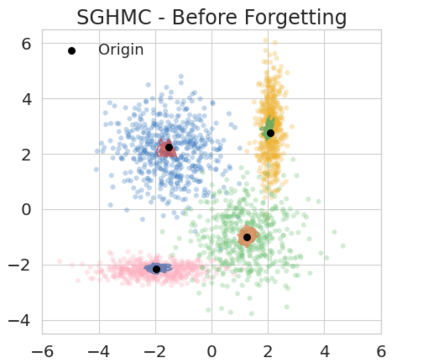
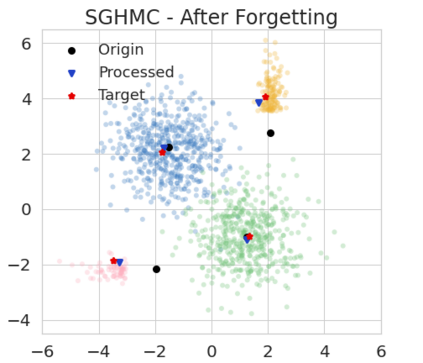
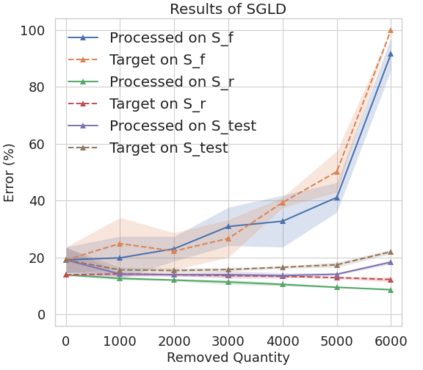
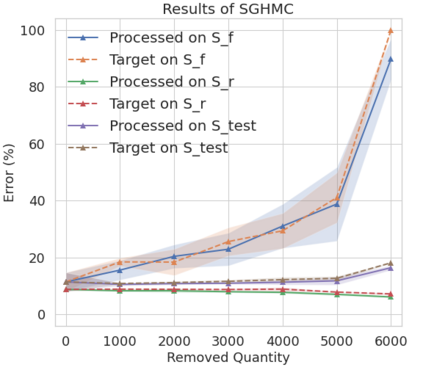
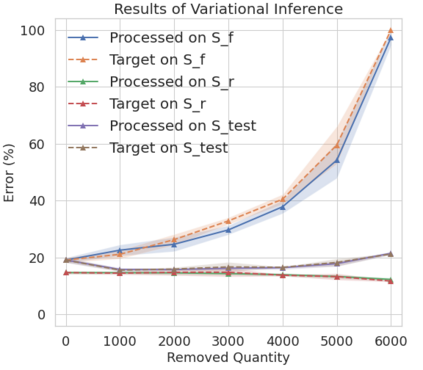
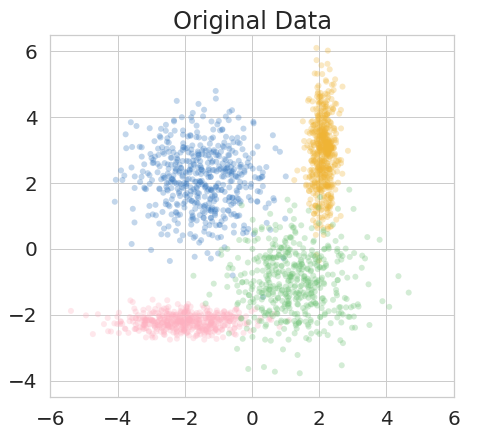
The right to be forgotten has been legislated in many countries but the enforcement in machine learning would cause unbearable costs: companies may need to delete whole models learned from massive resources due to single individual requests. Existing works propose to remove the knowledge learned from the requested data via its influence function which is no longer naturally well-defined in Bayesian inference. This paper proposes a {\it Bayesian inference forgetting} (BIF) framework to realize the right to be forgotten in Bayesian inference. In the BIF framework, we develop forgetting algorithms for variational inference and Markov chain Monte Carlo. We show that our algorithms can provably remove the influence of single datums on the learned models. Theoretical analysis demonstrates that our algorithms have guaranteed generalizability. Experiments of Gaussian mixture models on the synthetic dataset and Bayesian neural networks on the real-world data verify the feasibility of our methods. The source code package is available at \url{https://github.com/fshp971/BIF}.
翻译:被遗忘的权利已经在许多国家得到立法,但机器学习的强制执行将造成无法承受的成本:公司可能需要删除由于单一个人请求而从大量资源中汲取的全部模型; 现有的工程提议通过其影响功能从所要求的数据中汲取知识,而这种影响功能在巴伊西亚推论中已不再自然地明确界定。 本文提出了一个在巴伊西亚推论中实现被遗忘的权利的框架。 在BIF框架内,我们开发了用于变异性判断的算法和Markov链的蒙特卡洛。 我们表明我们的算法可以消除单数据对所学模型的影响。 理论分析表明,我们的算法已经保证了可概括性。 在合成数据集上加西亚混合模型的实验和现实世界数据上的巴伊西亚神经网络验证了我们方法的可行性。 源代码包可以在https://github.com/fshp971/BIF}上查阅。