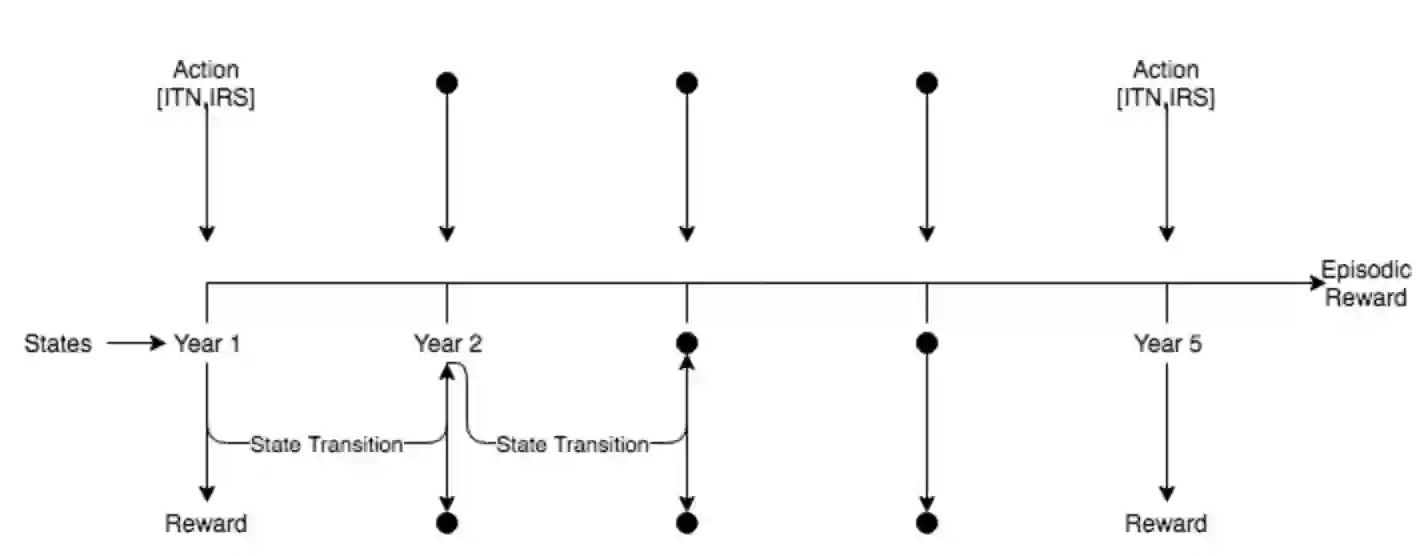
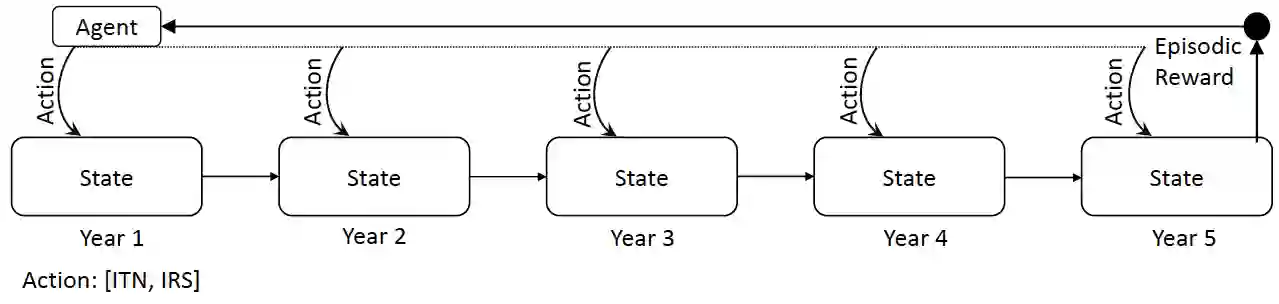
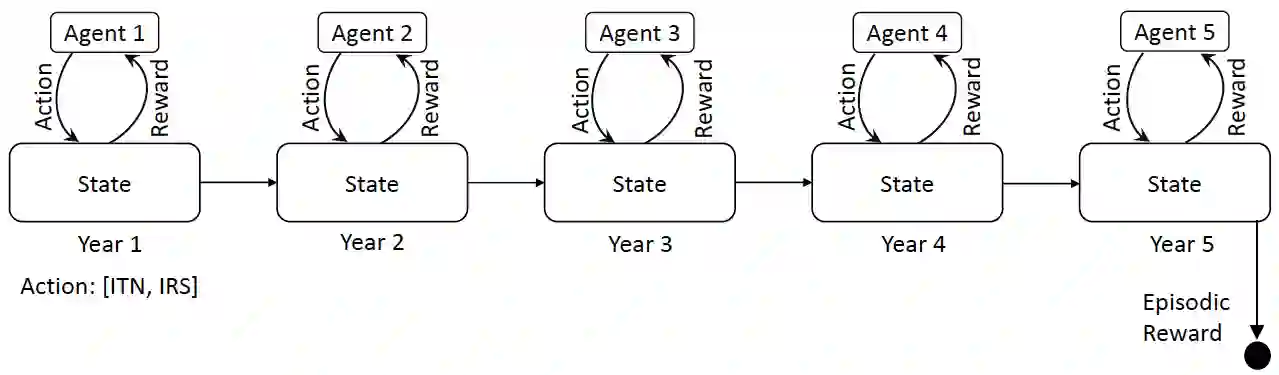
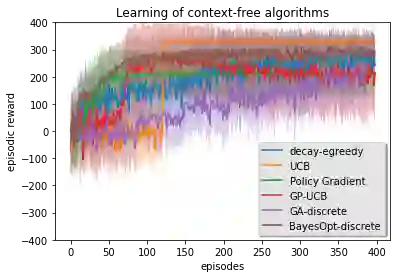
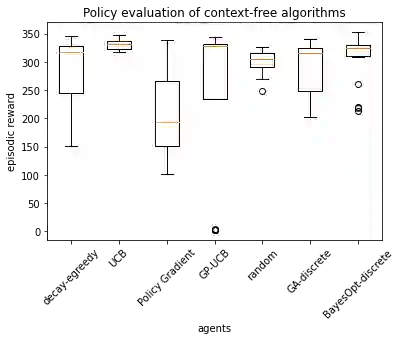
Previous work on policy learning for Malaria control has often formulated the problem as an optimization problem assuming the objective function and the search space have a specific structure. The problem has been formulated as multi-armed bandits, contextual bandits and a Markov Decision Process in isolation. Furthermore, an emphasis is put on developing new algorithms specific to an instance of Malaria control, while ignoring a plethora of simpler and general algorithms in the literature. In this work, we formally study the formulation of Malaria control and present a comprehensive analysis of several formulations used in the literature. In addition, we implement and analyze several reinforcement learning algorithms in all formulations and compare them to black box optimization. In contrast to previous work, our results show that simple algorithms based on Upper Confidence Bounds are sufficient for learning good Malaria policies, and tend to outperform their more advanced counterparts on the malaria OpenAI Gym environment.
翻译:以往疟疾控制政策学习工作往往将问题发展为假设客观功能和搜索空间具有特定结构的优化问题,这个问题是孤立地作为多武装强盗、背景强盗和马尔科夫决策程序形成的;此外,强调发展疟疾控制实例特有的新算法,同时忽视文献中大量简单和一般的算法;在这项工作中,我们正式研究疟疾控制方法的制定,并对文献中使用的几种配方进行全面分析;此外,我们在所有配方中实施和分析若干强化学习算法,并将其与黑盒优化进行比较;与以往的工作不同,我们的结果显示,基于超信任网的简单算法足以学习良好的疟疾政策,并往往在疟疾 OpenAI Gym 环境中超越较先进的对应方。