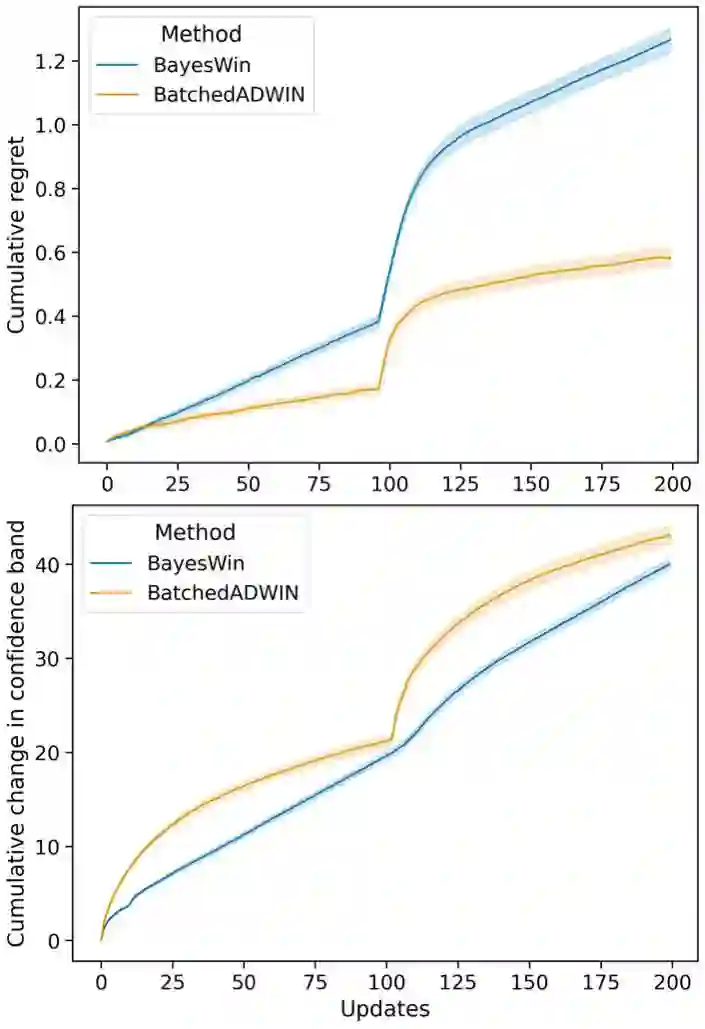
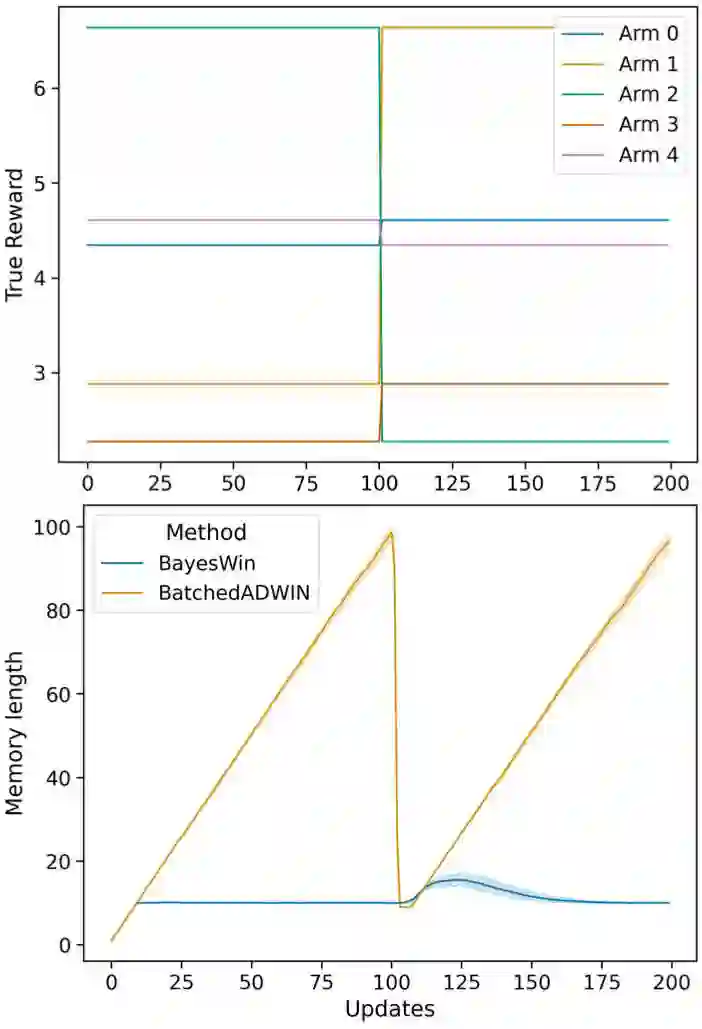
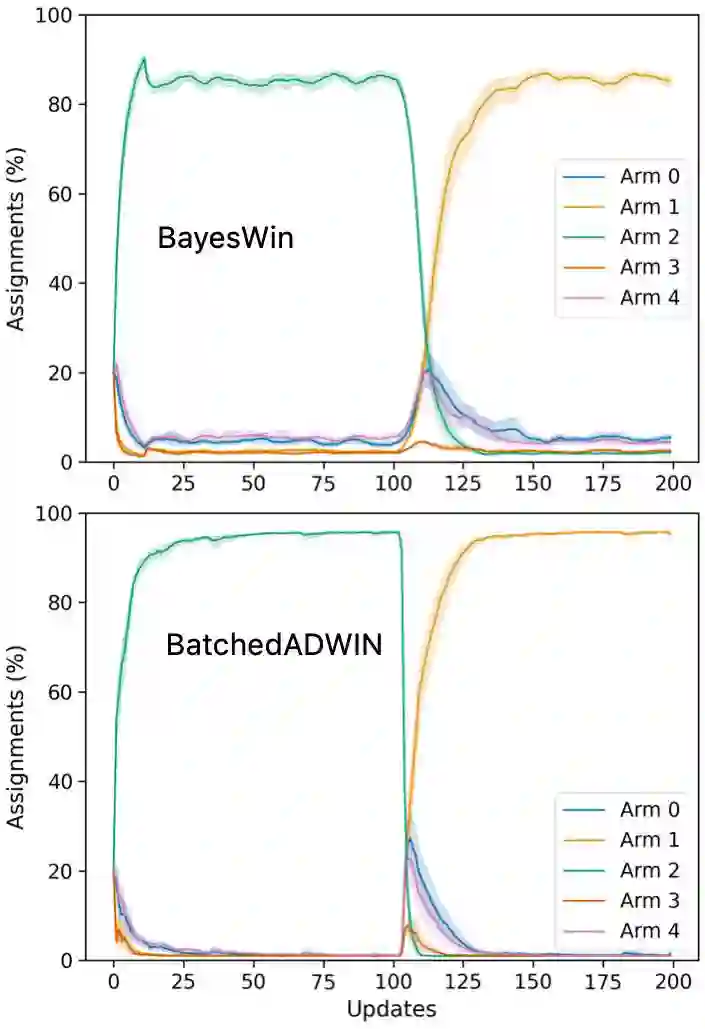
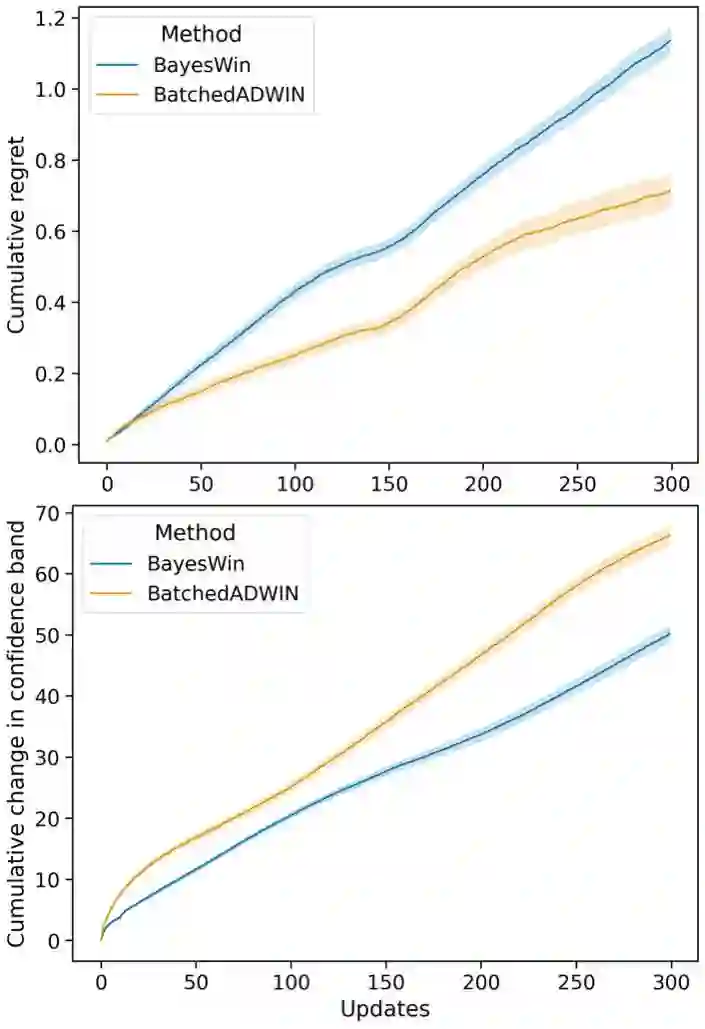
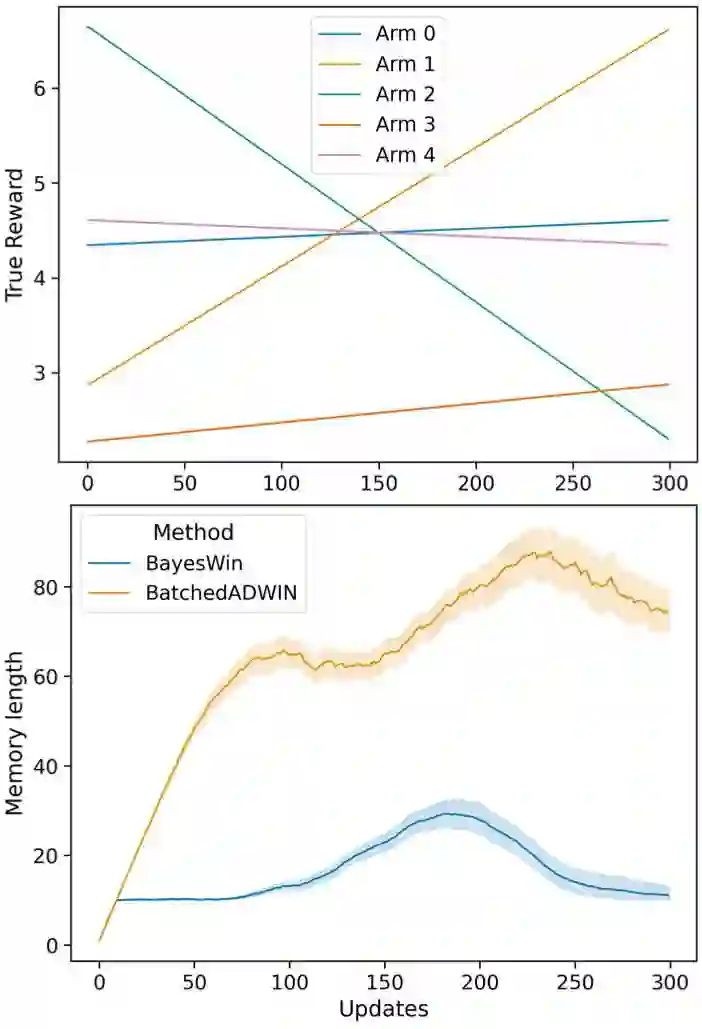
Real-world applications of reinforcement learning for recommendation and experimentation faces a practical challenge: the relative reward of different bandit arms can evolve over the lifetime of the learning agent. To deal with these non-stationary cases, the agent must forget some historical knowledge, as it may no longer be relevant to minimise regret. We present a solution to handling non-stationarity that is suitable for deployment at scale, to provide business operators with automated adaptive optimisation. Our solution aims to provide interpretable learning that can be trusted by humans, whilst responding to non-stationarity to minimise regret. To this end, we develop an adaptive Bayesian learning agent that employs a novel form of dynamic memory. It enables interpretability through statistical hypothesis testing, by targeting a set point of statistical power when comparing rewards and adjusting its memory dynamically to achieve this power. By design, the agent is agnostic to different kinds of non-stationarity. Using numerical simulations, we compare its performance against an existing proposal and show that, under multiple non-stationary scenarios, our agent correctly adapts to real changes in the true rewards. In all bandit solutions, there is an explicit trade-off between learning and achieving maximal performance. Our solution sits on a different point on this trade-off when compared to another similarly robust approach: we prioritise interpretability, which relies on more learning, at the cost of some regret. We describe the architecture of a large-scale deployment of automatic optimisation-as-a-service where our agent achieves interpretability whilst adapting to changing circumstances.
翻译:在现实世界中,强化学习用于建议和实验,面临一个实际挑战:不同土匪手臂的相对奖赏可以在学习代理人的一生中演变。为了处理这些非静止案例,代理人必须忘记一些历史知识,因为这可能不再与最大限度地减少遗憾相关。我们提出了一个解决方案,以处理适合大规模部署的非静止现象,为商业经营者提供自动适应性优化。我们的解决方案旨在提供可解释的学习,这种学习可以由人类信赖,同时对非静止情况作出反应,以尽可能减少遗憾。为此,我们开发了一个适应性的贝叶斯族学习代理人,采用动态记忆的新形式。为了处理这些非静止案例,代理人必须忘记一些历史知识,因为可能不再与最大限度地减少遗憾相关。我们提出了处理非静止现象的解决办法。我们用数字模拟,我们将其业绩与现有的提议进行比较,并表明,在多种非静止假设情况下,我们的代理人正确地适应真正的变化。在所有不稳定的解决方案中,通过统计假设一个固定的统计力量点,让我们在更明显的贸易灵活性上进行明确的贸易性调整,从而实现我们之前进行最严格的解释。