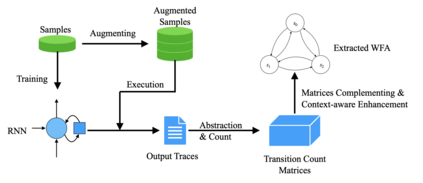
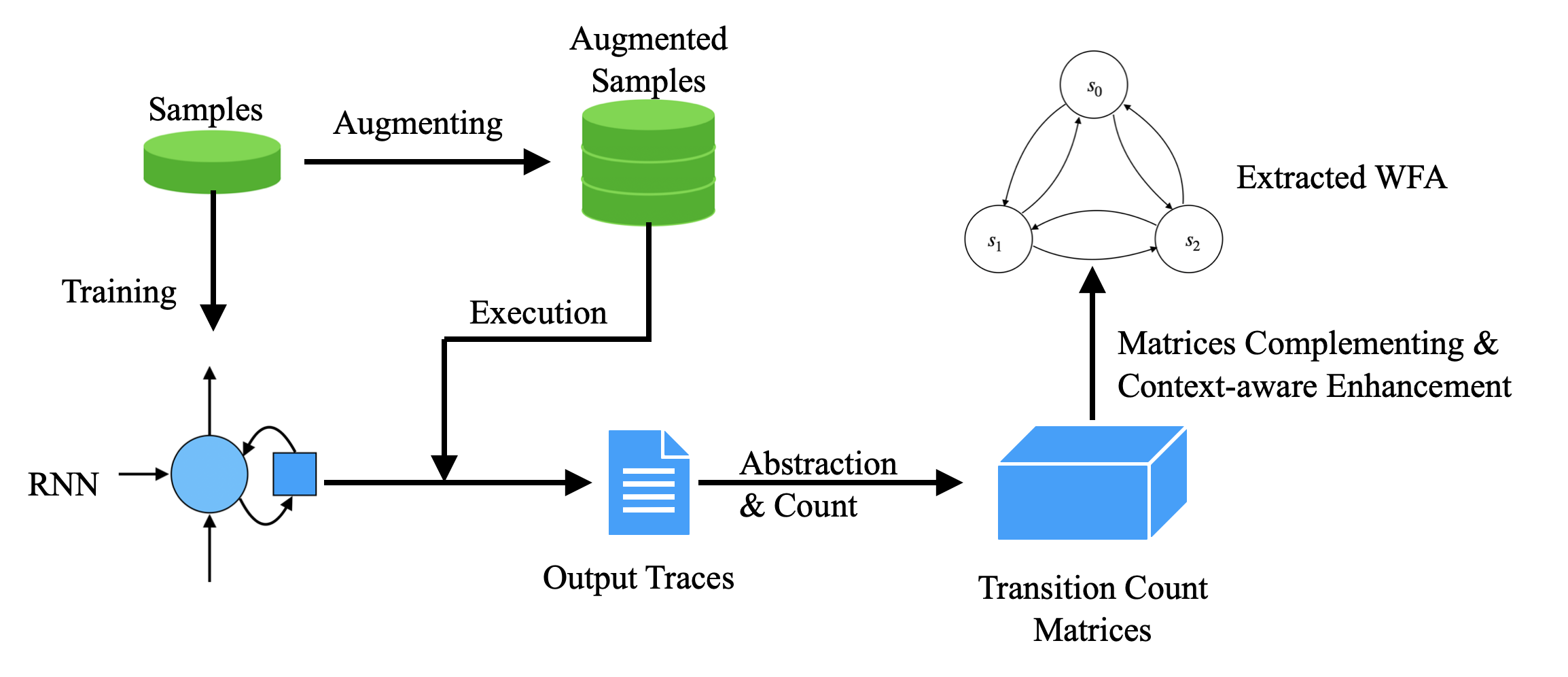
Recurrent Neural Networks (RNNs) have achieved tremendous success in sequential data processing. However, it is quite challenging to interpret and verify RNNs' behaviors directly. To this end, many efforts have been made to extract finite automata from RNNs. Existing approaches such as exact learning are effective in extracting finite-state models to characterize the state dynamics of RNNs for formal languages, but are limited in the scalability to process natural languages. Compositional approaches that are scablable to natural languages fall short in extraction precision. In this paper, we identify the transition sparsity problem that heavily impacts the extraction precision. To address this problem, we propose a transition rule extraction approach, which is scalable to natural language processing models and effective in improving extraction precision. Specifically, we propose an empirical method to complement the missing rules in the transition diagram. In addition, we further adjust the transition matrices to enhance the context-aware ability of the extracted weighted finite automaton (WFA). Finally, we propose two data augmentation tactics to track more dynamic behaviors of the target RNN. Experiments on two popular natural language datasets show that our method can extract WFA from RNN for natural language processing with better precision than existing approaches. Our code is available at https://github.com/weizeming/Extract_WFA_from_RNN_for_NL.
翻译:经常性神经网络(Neal Networks)在连续处理数据方面取得了巨大的成功,然而,直接解释和核实RNNs的行为是相当困难的。为此,我们已作出许多努力,从RNS中提取有限的自动数据。现有的方法,例如精确学习,在为正式语言提取限定国家的状态动态模型方面是有效的,但是在可缩放性方面是有限的,但在处理自然语言方面是有限的。对自然语言的定性方法(WFA),在提取精度方面还远远不够精确。在本文中,我们找出了严重影响提取精确度的过渡性过度性问题。为了解决这一问题,我们建议采用过渡性规则提取方法,该方法可与自然语言处理模型相适应,并有效地改进提取精确度。具体地说,我们提出了一个实验方法,以补充过渡图中缺失的规则。此外,我们进一步调整了过渡矩阵,以加强抽取的加权自动地图(WFA)。最后,我们提议了两种数据增强能力的方法,以跟踪目标RNNE(RN)的动态行为。在两种通用的自然语言数据处理中进行实验,这两次比我们现有的自然语言精确处理方法可以提取。