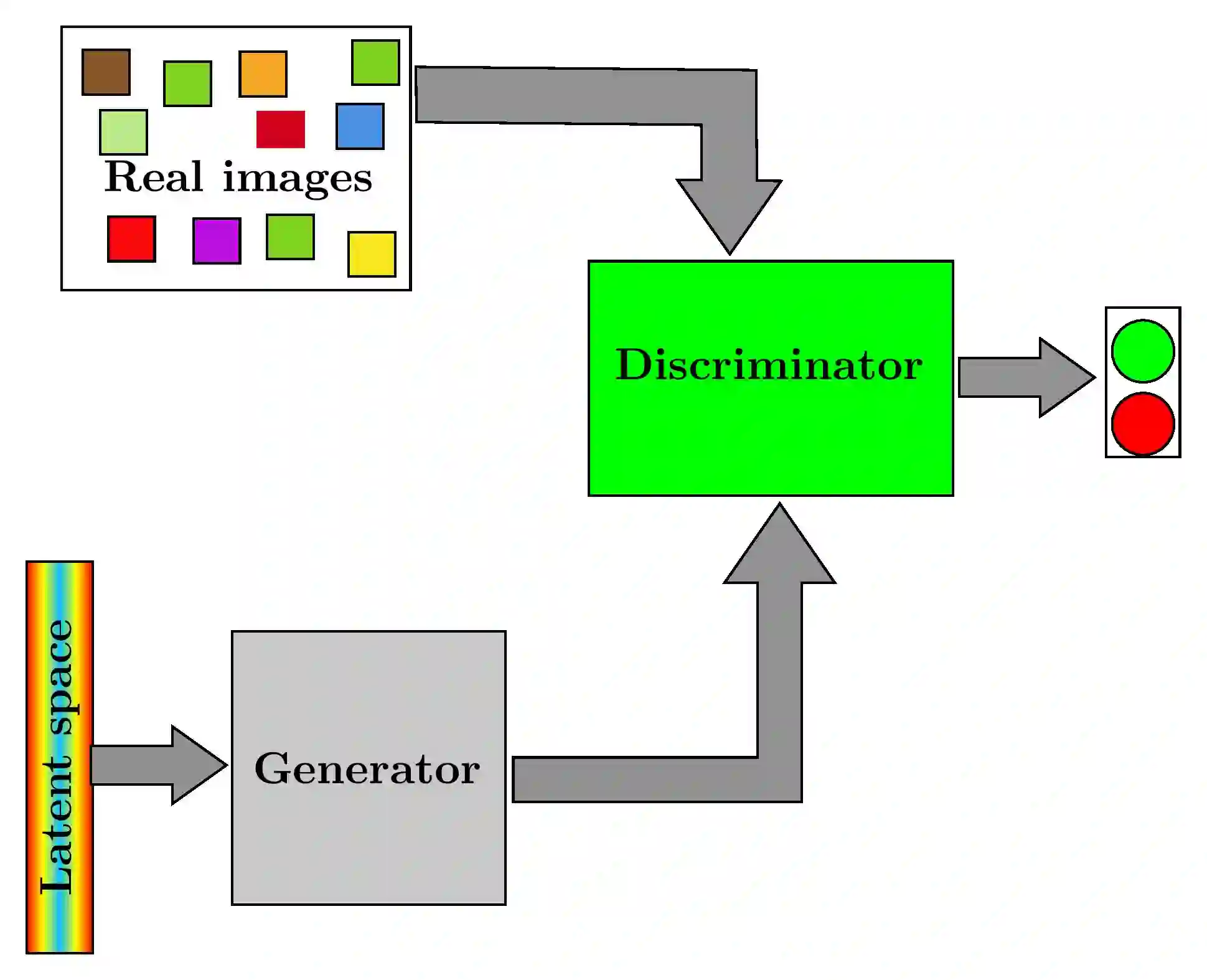
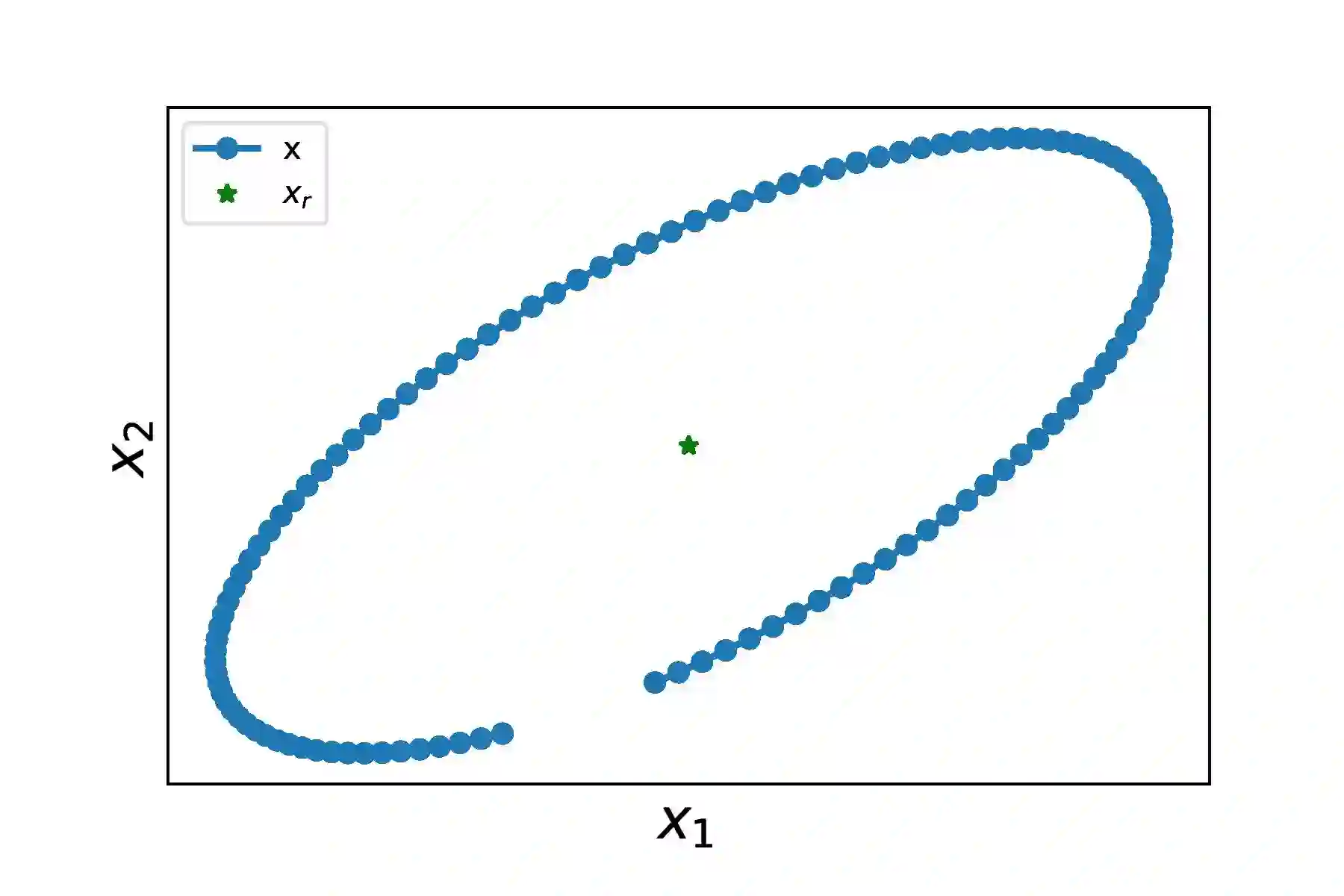
Fitting neural networks often resorts to stochastic (or similar) gradient descent which is a noise-tolerant (and efficient) resolution of a gradient descent dynamics. It outputs a sequence of networks parameters, which sequence evolves during the training steps. The gradient descent is the limit, when the learning rate is small and the batch size is infinite, of this set of increasingly optimal network parameters obtained during training. In this contribution, we investigate instead the convergence in the Generative Adversarial Networks used in machine learning. We study the limit of small learning rate, and show that, similar to single network training, the GAN learning dynamics tend, for vanishing learning rate to some limit dynamics. This leads us to consider evolution equations in metric spaces (which is the natural framework for evolving probability laws)that we call dual flows. We give formal definitions of solutions and prove the convergence. The theory is then applied to specific instances of GANs and we discuss how this insight helps understand and mitigate the mode collapse.
翻译:合适的神经网络往往采用随机( 或类似的) 梯度下降, 这是一种对梯度下降动态的耐噪( 和高效) 解析方法。 它输出一系列网络参数, 在培训步骤中演化。 当学习率小, 批量大小无限时, 梯度下降是这组在培训期间获得的日益最佳的网络参数的极限。 在此贡献中, 我们调查机器学习中使用的基因对流网络的趋同性。 我们研究小学习率的限度, 并显示, 和单一网络培训一样, 学习率的GAN学习动力趋势, 以消失到某些限制动态。 这导致我们考虑在量空间的进化方程式( 这是演进概率法的自然框架 ) 。 我们给出了解决方案的正式定义, 并证明这些趋同性。 然后将理论应用到 GAN 的具体实例中, 我们讨论这种洞察如何帮助理解和减轻模式崩溃 。