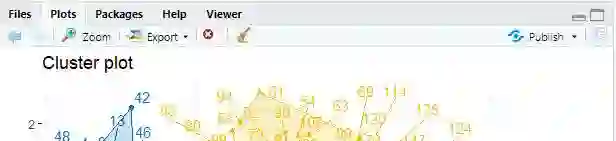
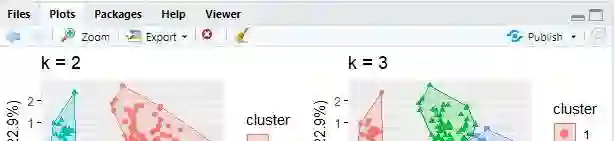
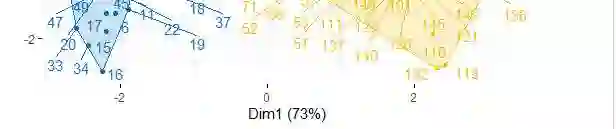The objectives of this paper are to explore ways to analyze breast cancer dataset in the context of unsupervised learning without prior training model. The paper investigates different ways of clustering techniques as well as preprocessing. This in-depth analysis builds the footprint which can further use for designing a most robust and accurate medical prognosis system. This paper also give emphasis on correlations of data points with different standard benchmark techniques. Keywords: Breast cancer dataset, Clustering Technique Hopkins Statistic, K-means Clustering, k-medoids or partitioning around medoids (PAM)
翻译:本文件的目的是探讨在未经事先培训模式的情况下,在未经监督的学习背景下分析乳腺癌数据集的方法。本文调查了集群技术和预处理的不同方式。这一深入分析建立了足迹,可以进一步用于设计最可靠和最准确的医疗预测系统。本文还强调了数据点与不同标准基准技术的相互关系。关键词:乳腺癌数据集、组合技术霍普金斯统计、K手段组群、k型类或围绕类动物的分割。