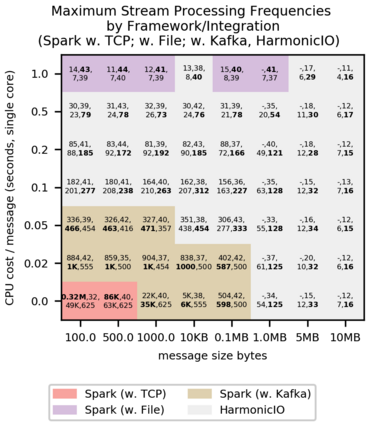
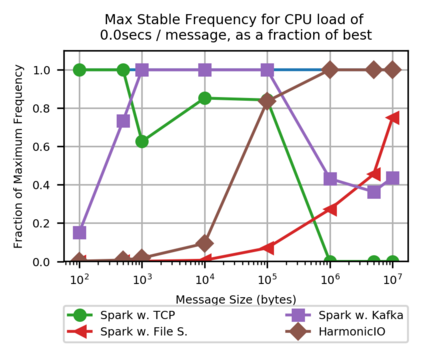
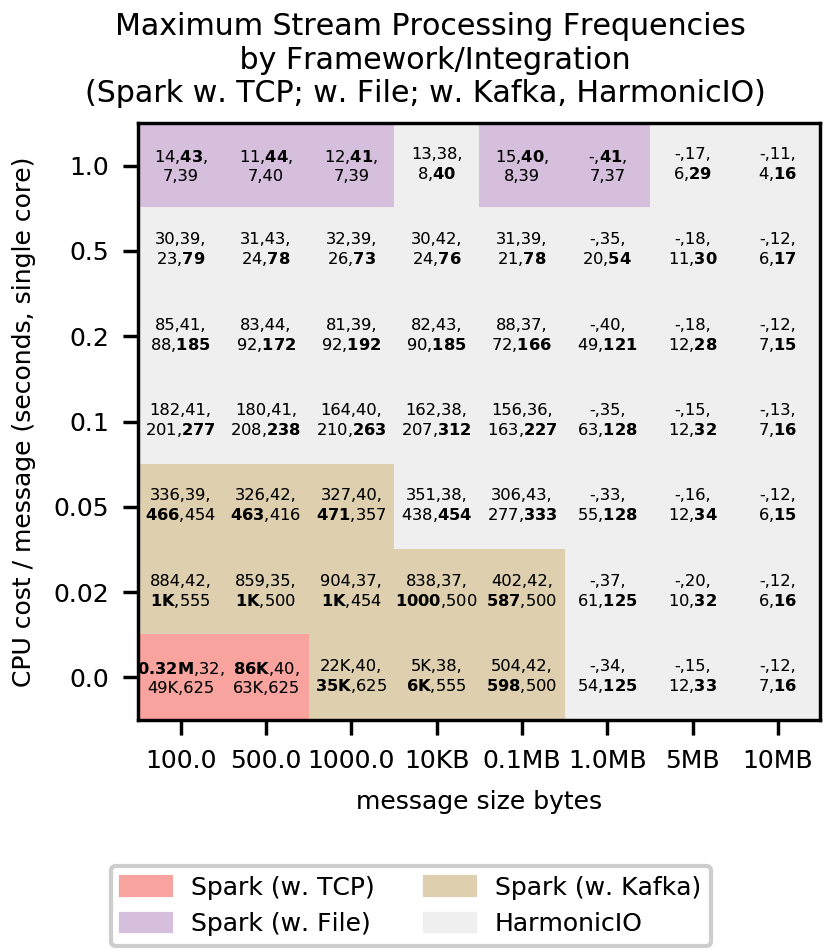
This paper presents a benchmark of stream processing throughput comparing Apache Spark Streaming (under file-, TCP socket- and Kafka-based stream integration), with a prototype P2P stream processing framework, HarmonicIO. Maximum throughput for a spectrum of stream processing loads are measured, specifically, those with large message sizes (up to 10MB), and heavy CPU loads -- more typical of scientific computing use cases (such as microscopy), than enterprise contexts. A detailed exploration of the performance characteristics with these streaming sources, under varying loads, reveals an interplay of performance trade-offs, uncovering the boundaries of good performance for each framework and streaming source integration. We compare with theoretic bounds in each case. Based on these results, we suggest which frameworks and streaming sources are likely to offer good performance for a given load. Broadly, the advantages of Spark's rich feature set comes at a cost of sensitivity to message size in particular -- common stream source integrations can perform poorly in the 1MB-10MB range. The simplicity of HarmonicIO offers more robust performance in this region, especially for raw CPU utilization.
翻译:本文介绍了将Apache Spark Streaming(在文件、TCP Socket-和Kafka基流流集成下)与原型P2P流处理框架 " 和谐组织 " 比较的溪流处理输送量基准。测量了流流处理负荷频谱的最大输送量,具体而言,测量了信息大小大(最高为10MB)和重的CPU负荷 -- -- 科学计算使用案例(如显微镜)比企业环境更为典型。详细探索这些流源的性能特点(在不同的负荷下),揭示了业绩权衡的相互作用,揭示了每个框架和流源集集集集集集集的优良性能界限。我们根据这些结果,将每种情况与理论界限进行比较。根据这些结果,我们建议,哪些框架和流集水源可能对特定负荷提供良好的性能。广而言,Spark的丰富地谱集的好处是以特定信息大小的灵敏度为代价 -- -- 常见的流源集集集集在1MB- 10MB 范围中表现不佳。