
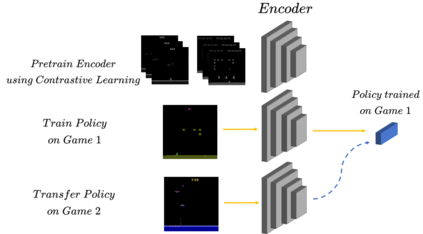
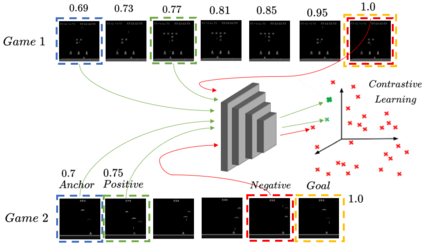
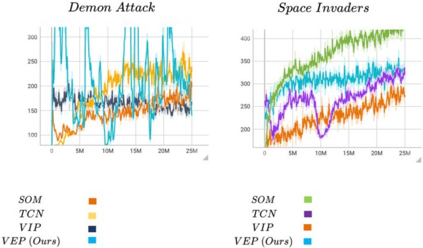
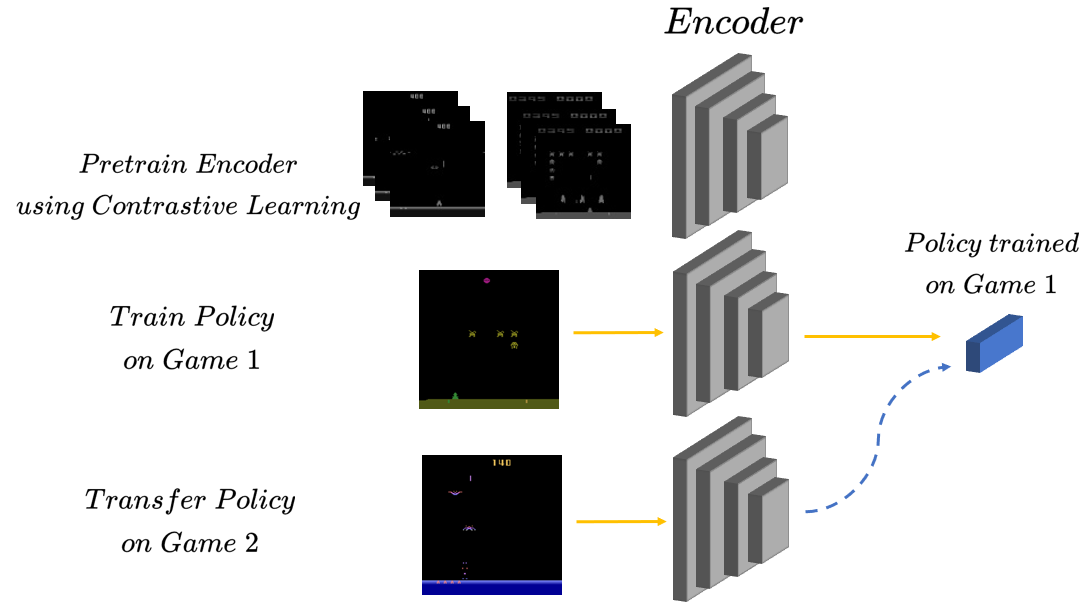
We propose a method that allows for learning task-agnostic representations based on value function estimates from a sequence of observations where the last frame corresponds to a goal. These representations would learn to relate states across different tasks, based on the temporal distance to the goal state, irrespective of the appearance changes and dynamics. This method could be used to transfer learnt policies/skills to unseen related tasks.
翻译:暂无翻译
相关内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2024年1月31日



相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯