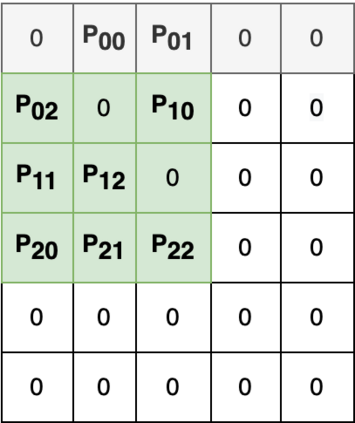
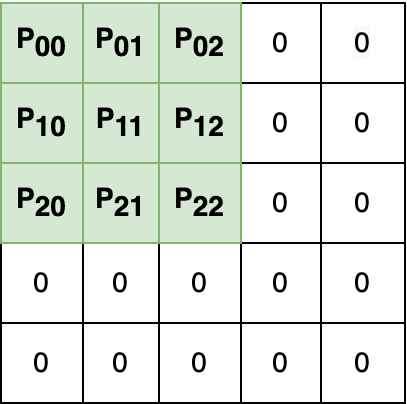
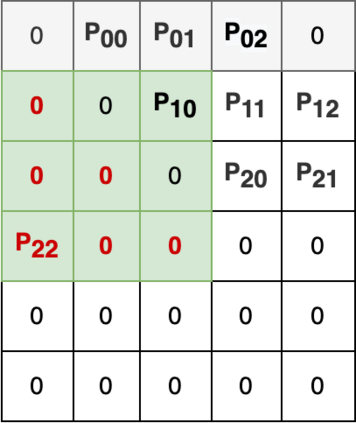
Despite its pivotal role in research experiments, code correctness is often presumed only on the basis of the perceived quality of the results. This comes with the risk of erroneous outcomes and potentially misleading findings. To address this issue, we posit that the current focus on result reproducibility should go hand in hand with the emphasis on coding best practices. We bolster our call to the NLP community by presenting a case study, in which we identify (and correct) three bugs in widely used open-source implementations of the state-of-the-art Conformer architecture. Through comparative experiments on automatic speech recognition and translation in various language settings, we demonstrate that the existence of bugs does not prevent the achievement of good and reproducible results and can lead to incorrect conclusions that potentially misguide future research. In response to this, this study is a call to action toward the adoption of coding best practices aimed at fostering correctness and improving the quality of the developed software.
翻译:尽管其在研究实验中具有关键作用,但代码正确性通常只基于结果质量的感知被认定。这会带来错误结果和潜在的误导性发现的风险。为解决这个问题,我们认为当前对结果可重复性的关注应该与对编码最佳实践的强调相辅相成。通过案例研究,我们证明了这一点,我们在其中识别(和纠正)了当前广泛使用的最先进的Conformer结构的开源实现中的三个错误。通过对各种语言设置中的自动语音识别和翻译的比较实验,我们证明了错误的存在并不会阻止实现良好和可重复的结果,并且可能导致不正确的结论,从而潜在地误导未来的研究。为了应对这个问题,这项研究呼吁采用旨在促进正确性和提高开发软件质量的编码最佳实践。