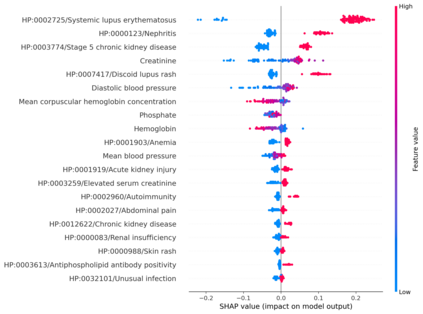
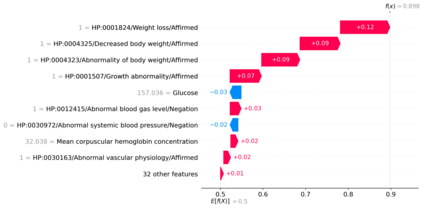
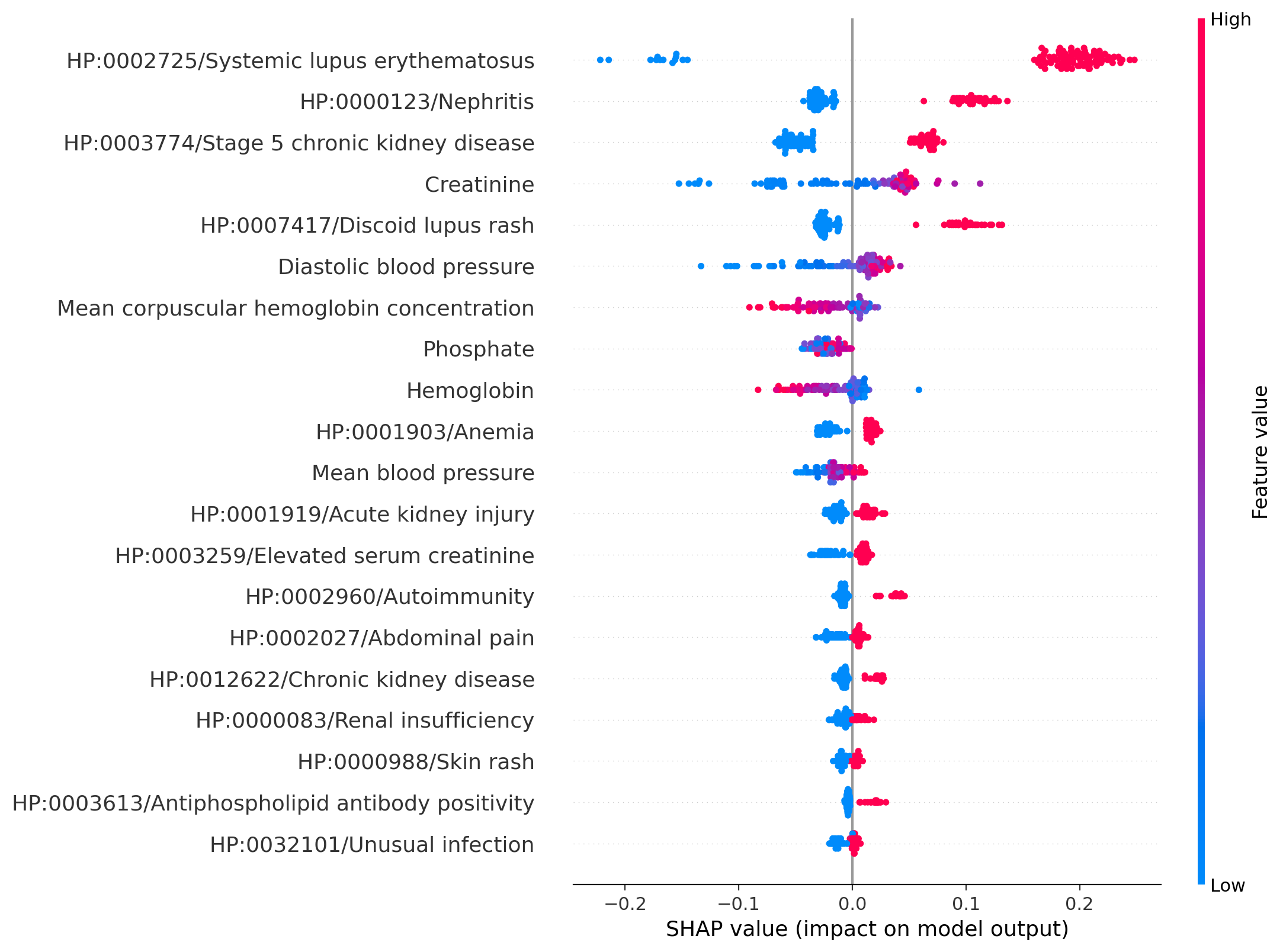
Clinicians may rely on medical coding systems such as International Classification of Diseases (ICD) to identify patients with diseases from Electronic Health Records (EHRs). However, due to the lack of detail and specificity as well as a probability of miscoding, recent studies suggest the ICD codes often cannot characterise patients accurately for specific diseases in real clinical practice, and as a result, using them to find patients for studies or trials can result in high failure rates and missing out on uncoded patients. Manual inspection of all patients at scale is not feasible as it is highly costly and slow. This paper proposes a scalable workflow which leverages both structured data and unstructured textual notes from EHRs with techniques including NLP, AutoML and Clinician-in-the-Loop mechanism to build machine learning classifiers to identify patients at scale with given diseases, especially those who might currently be miscoded or missed by ICD codes. Case studies in the MIMIC-III dataset were conducted where the proposed workflow demonstrates a higher classification performance in terms of F1 scores compared to simply using ICD codes on gold testing subset to identify patients with Ovarian Cancer (0.901 vs 0.814), Lung Cancer (0.859 vs 0.828), Cancer Cachexia (0.862 vs 0.650), and Lupus Nephritis (0.959 vs 0.855). Also, the proposed workflow that leverages unstructured notes consistently outperforms the baseline that uses structured data only with an increase of F1 (Ovarian Cancer 0.901 vs 0.719, Lung Cancer 0.859 vs 0.787, Cancer Cachexia 0.862 vs 0.838 and Lupus Nephritis 0.959 vs 0.785). Experiments on the large testing set also demonstrate the proposed workflow can find more patients who are miscoded or missed by ICD codes. Moreover, interpretability studies are also conducted to clinically validate the top impact features of the classifiers.
翻译:临床医生可能依靠国际疾病分类(ICD)等医学编码系统来识别来自电子健康记录(EHRs)的疾病患者。 但是,由于缺乏细节和具体性以及错误编码的概率,最近的研究表明,在实际临床实践中,ICD代码往往不能准确描述患者对特定疾病的特点,因此,利用他们寻找患者进行研究或试验,可能导致高失败率或对未编码患者的缺失。对所有患者的手工检查并不可行,因为其规模成本和速度都很高。本文提议了一个可升级的工作流程,利用EHR的结构性数据和非结构化文本说明,使用包括NLP、AutalML和临床医生(LOop)在内的技术,来建立机器学习分类,以辨别特定疾病的规模,尤其是那些目前可能被ICD编码错误或误算的患者。 MIMIC-III数据集的案例研究只能通过F1的分类表现更高。 与简单地使用ICD测试基子的ICD数据相比,使用OLO.