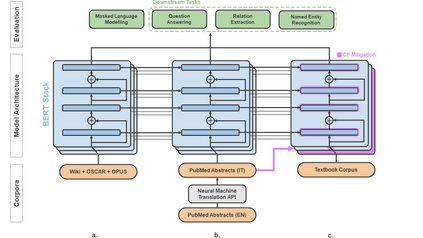
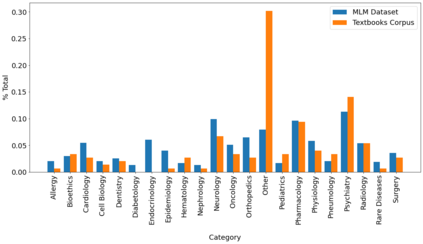
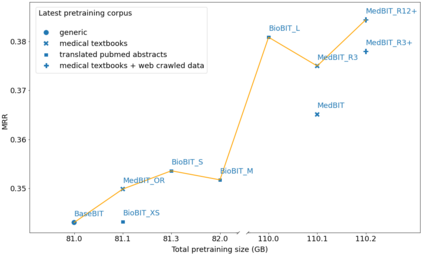
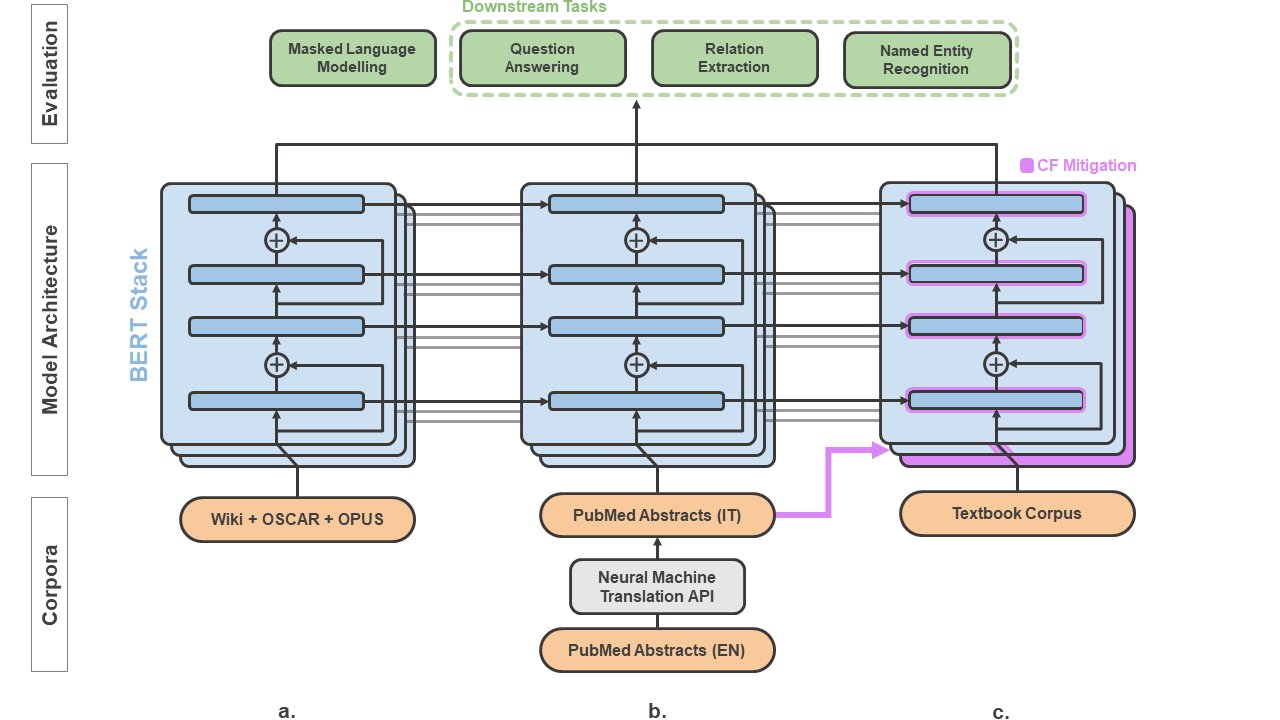
In the era of digital healthcare, the huge volumes of textual information generated every day in hospitals constitute an essential but underused asset that could be exploited with task-specific, fine-tuned biomedical language representation models, improving patient care and management. For such specialized domains, previous research has shown that fine-tuning models stemming from broad-coverage checkpoints can largely benefit additional training rounds over large-scale in-domain resources. However, these resources are often unreachable for less-resourced languages like Italian, preventing local medical institutions to employ in-domain adaptation. In order to reduce this gap, our work investigates two accessible approaches to derive biomedical language models in languages other than English, taking Italian as a concrete use-case: one based on neural machine translation of English resources, favoring quantity over quality; the other based on a high-grade, narrow-scoped corpus natively in Italian, thus preferring quality over quantity. Our study shows that data quantity is a harder constraint than data quality for biomedical adaptation, but the concatenation of high-quality data can improve model performance even when dealing with relatively size-limited corpora. The models published from our investigations have the potential to unlock important research opportunities for Italian hospitals and academia. Finally, the set of lessons learned from the study constitutes valuable insights towards a solution to build biomedical language models that are generalizable to other less-resourced languages and different domain settings.
翻译:在数字保健时代,医院每天产生的大量文字信息构成了一种重要但未充分利用的资产,可以通过具体任务、经过微调的生物医学语言代表模式加以利用,改善病人的护理和管理。在这种专门领域,先前的研究显示,广泛覆盖的检查站的微调模式可在很大程度上有利于大规模内部资源方面的更多培训回合;然而,这些资源往往无法用于像意大利这样的资源较少的语文,阻止当地医疗机构采用内部适应办法。为了缩小这一差距,我们的工作调查了两种可获得的方法,即用英语以外的语言来产生生物医学语言模型,将意大利语作为具体的使用案例:一种基于英语资源的神经机器翻译,偏重质量;另一种基于意大利本土高等级、狭义的建筑,从而优于数量。然而,我们的研究表明,数据数量比数据质量更难以限制生物医学适应,但高品质数据的配置可以提高模型的性能,即使处理相对规模有限的子科罗拉语,但将意大利语作为具体的使用案例:一种基于英语资源的神经机器翻译,偏重质量优于质量;另一种基于意大利语本的研究模型,最终形成了一种重要的研究机会,从意大利通用的大学学习到其他的学术研究模式。