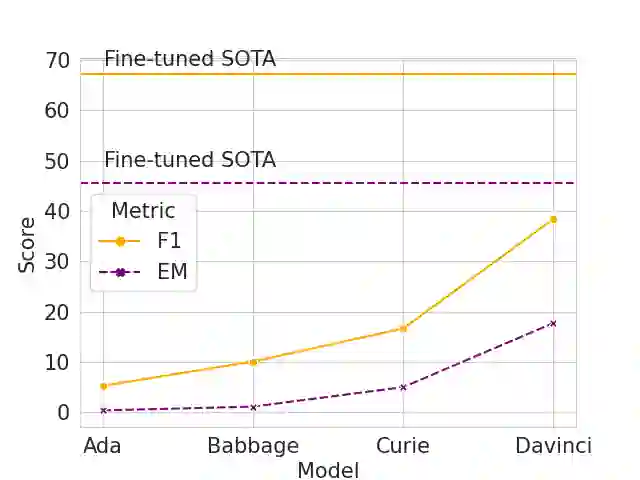
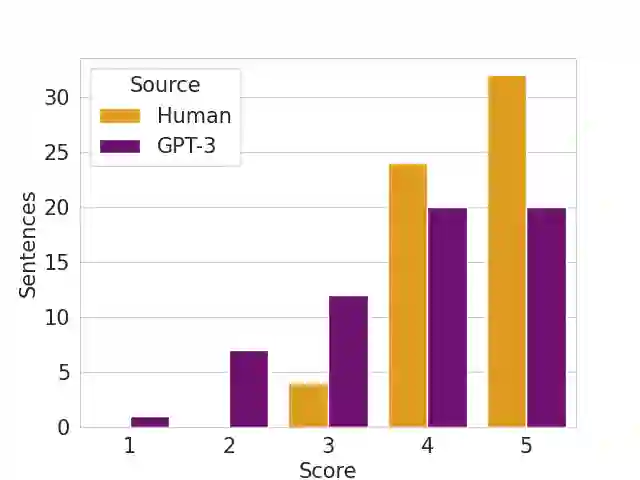
Generative Pre-trained Transformers (GPTs) have recently been scaled to unprecedented sizes in the history of machine learning. These models, solely trained on the language modeling objective, have been shown to exhibit outstanding few-shot learning capabilities in a number of different tasks. Nevertheless, aside from anecdotal experiences, little is known regarding their multilingual capabilities, given the fact that the pre-training corpus is almost entirely composed of English text. In this work, we investigate the multilingual skills of GPT-3, focusing on one language that barely appears in the pre-training corpus, Catalan, which makes the results especially meaningful; we assume that our results may be relevant for other languages as well. We find that the model shows an outstanding performance, particularly in generative tasks, with predictable limitations mostly in language understanding tasks but still with remarkable results given the zero-shot scenario. We investigate its potential and limits in extractive question-answering and natural language generation, as well as the effect of scale in terms of model size.
翻译:最近,在机器学习史上,经过培训的预产型变异器(GPTs)已发展到前所未有的规模,这些只受过语言建模目标培训的模型显示,在一些不同的任务中,这些模型表现出了杰出的微小学习能力,然而,除了传闻经验外,对于其多语种能力知之甚少,因为培训前的教材几乎完全由英文文本组成。在这项工作中,我们调查了GPT-3的多语种技能,侧重于在培训前教材中几乎没有出现的一种语言,即加泰罗尼亚语,结果特别有意义;我们假设我们的结果可能与其他语言相关。我们发现,该模型显示了一种杰出的成绩,特别是在基因化任务方面,主要在语言理解任务方面可以预见的局限性,但在零光学问答和自然语言生成方面仍然取得显著成果。我们调查了该模型在采掘问答和自然语言生成方面的潜力和局限性,以及规模的影响。