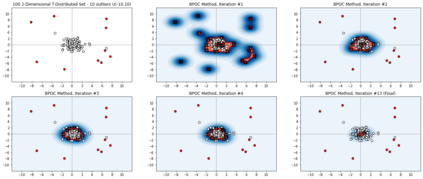
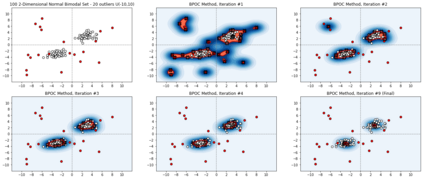
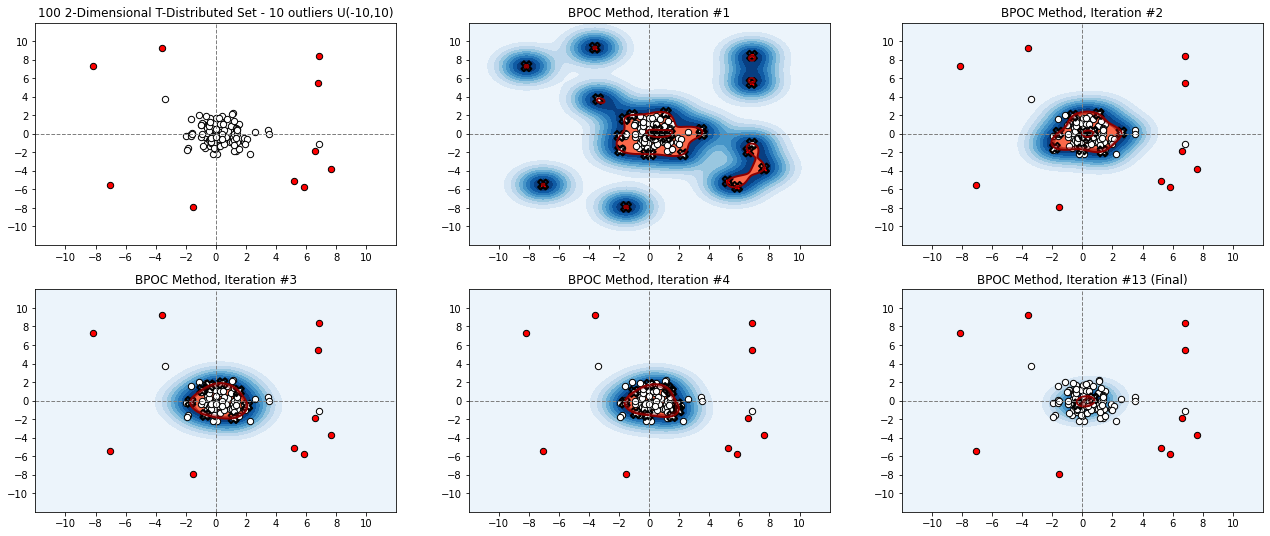
Unsupervised outlier detection constitutes a crucial phase within data analysis and remains a dynamic realm of research. A good outlier detection algorithm should be computationally efficient, robust to tuning parameter selection, and perform consistently well across diverse underlying data distributions. We introduce One-Class Boundary Peeling, an unsupervised outlier detection algorithm. One-class Boundary Peeling uses the average signed distance from iteratively-peeled, flexible boundaries generated by one-class support vector machines. One-class Boundary Peeling has robust hyperparameter settings and, for increased flexibility, can be cast as an ensemble method. In synthetic data simulations One-Class Boundary Peeling outperforms all state of the art methods when no outliers are present while maintaining comparable or superior performance in the presence of outliers, as compared to benchmark methods. One-Class Boundary Peeling performs competitively in terms of correct classification, AUC, and processing time using common benchmark data sets.
翻译:暂无翻译