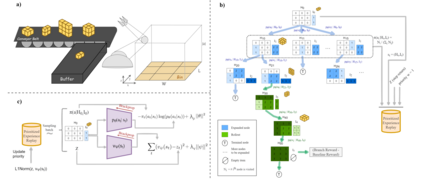
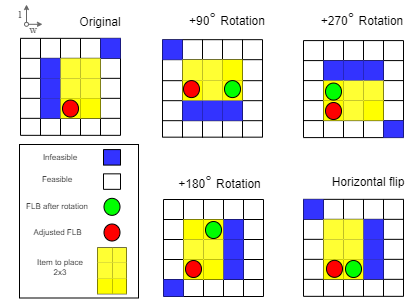
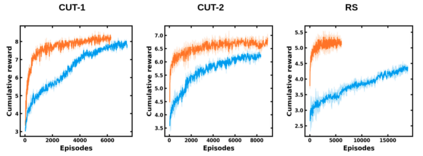
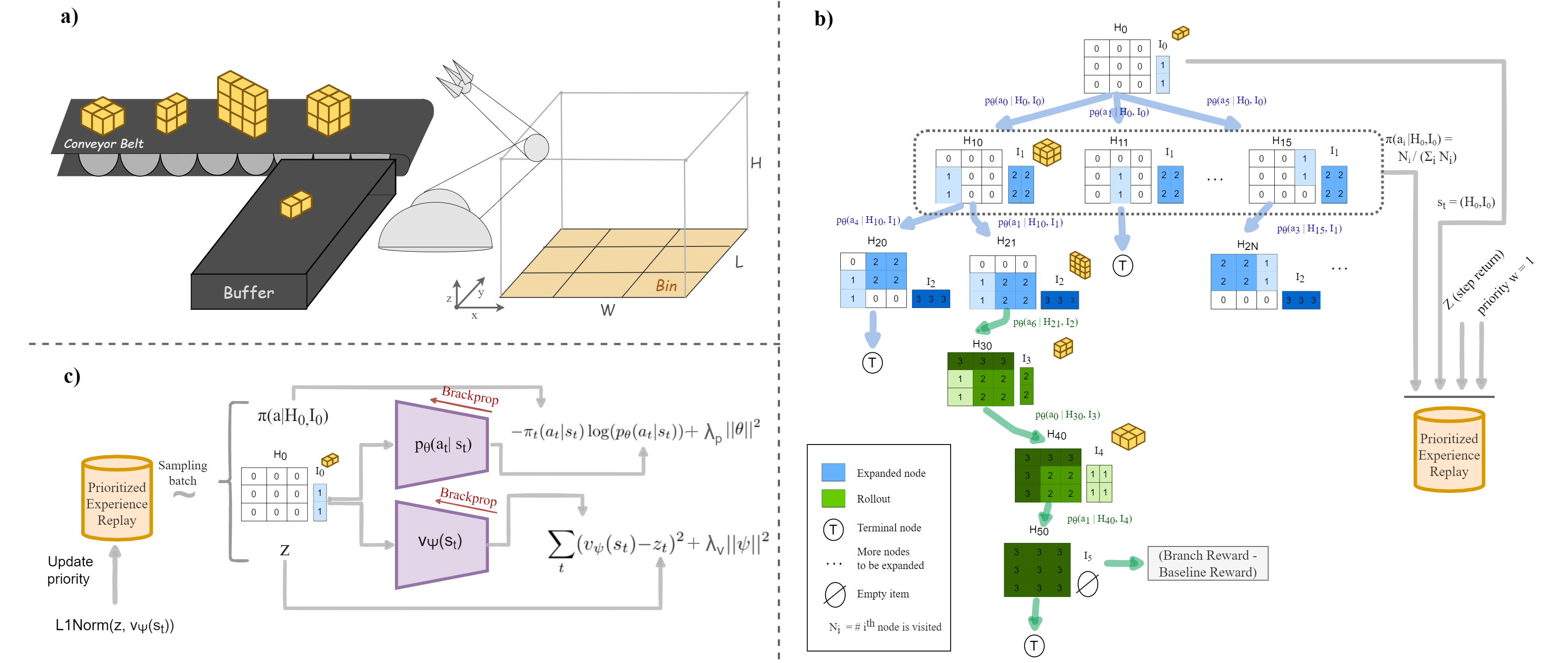
The 3D Bin Packing Problem (3D-BPP) is one of the most demanded yet challenging problems in industry, where an agent must pack variable size items delivered in sequence into a finite bin with the aim to maximize the space utilization. It represents a strongly NP-Hard optimization problem such that no solution has been offered to date with high performance in space utilization. In this paper, we present a new reinforcement learning (RL) framework for a 3D-BPP solution for improving performance. First, a buffer is introduced to allow multi-item action selection. By increasing the degree of freedom in action selection, a more complex policy that results in better packing performance can be derived. Second, we propose an agnostic data augmentation strategy that exploits both bin item symmetries for improving sample efficiency. Third, we implement a model-based RL method adapted from the popular algorithm AlphaGo, which has shown superhuman performance in zero-sum games. Our adaptation is capable of working in single-player and score based environments. In spite of the fact that AlphaGo versions are known to be computationally heavy, we manage to train the proposed framework with a single thread and GPU, while obtaining a solution that outperforms the state-of-the-art results in space utilization.
翻译:3D Bin包装问题 (3D-BPP) 是行业中最需要但最具挑战性的问题之一, 代理商必须把按顺序交付的可变大小项目包装成一个有限的垃圾箱, 以便最大限度地实现空间利用。 它是一个强烈的NP- Hard优化问题, 至今尚未提出空间利用性能高的解决方案。 在本文中, 我们为3D- BPP改进性能解决方案提出了一个新的强化学习框架( RL) 。 首先, 引入一个缓冲, 允许多项目动作选择 。 通过提高行动选择的自由度, 可以产生一个更复杂的政策, 从而导致更好的包装性能。 第二, 我们提出一个不可知性的数据增强战略, 利用两个宾项组合来提高样本效率。 第三, 我们实施了一个基于模型的 RLEGO 方法, 从流行的算法中得到了超人性能, 在零和游戏中表现出超人性能。 我们的适应能够在单人性环境里工作, 并且基于分分数。 尽管人们知道阿尔法 Go 版本在计算上是重的, 我们设法用一个单一的版本, 但是我们设法用了一个单一的公式和GPU 格式来训练一个单一的版本, 。