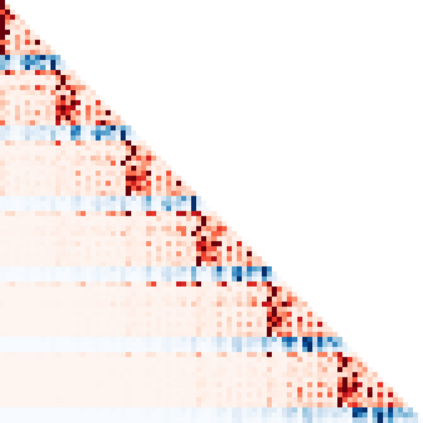
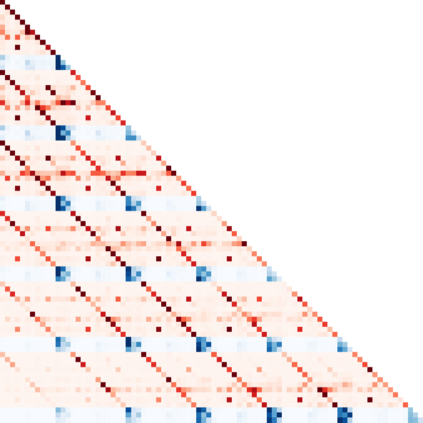
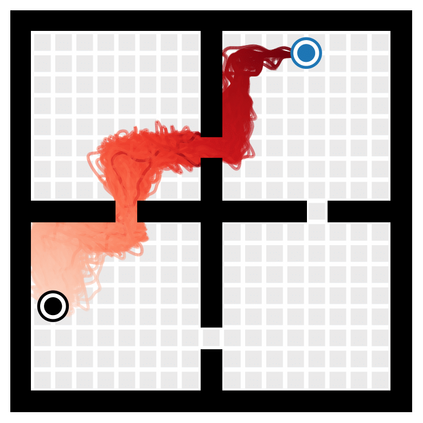
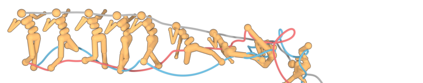Reinforcement learning (RL) is typically concerned with estimating single-step policies or single-step models, leveraging the Markov property to factorize the problem in time. However, we can also view RL as a sequence modeling problem, with the goal being to predict a sequence of actions that leads to a sequence of high rewards. Viewed in this way, it is tempting to consider whether powerful, high-capacity sequence prediction models that work well in other domains, such as natural-language processing, can also provide simple and effective solutions to the RL problem. To this end, we explore how RL can be reframed as "one big sequence modeling" problem, using state-of-the-art Transformer architectures to model distributions over sequences of states, actions, and rewards. Addressing RL as a sequence modeling problem significantly simplifies a range of design decisions: we no longer require separate behavior policy constraints, as is common in prior work on offline model-free RL, and we no longer require ensembles or other epistemic uncertainty estimators, as is common in prior work on model-based RL. All of these roles are filled by the same Transformer sequence model. In our experiments, we demonstrate the flexibility of this approach across long-horizon dynamics prediction, imitation learning, goal-conditioned RL, and offline RL.
翻译:强化学习( RL) 通常涉及估算单步政策或单步模式, 利用 Markov 属性来将问题及时化。 但是, 我们还可以将 RL 视为一个序列建模问题, 目标是预测一系列导致一系列高回报序列的行动。 从这个角度来看, 需要考虑在其它领域( 如自然语言处理) 行之有效的强大、 高容量序列预测模型是否也能为 RL 问题提供简单有效的解决方案。 为此, 我们探索如何将 RL 重新设定为“ 一大序列建模” 问题, 使用最先进的变换器结构来模拟国家、 行动和奖励序列的分布。 解决 RL 的排序问题, 大大简化了一系列设计决定: 我们不再需要单独的行为政策限制, 以往关于无主模式RL 的工作通常如此, 我们不再需要组合或其他缩略图的不确定性估测计, 正如以前关于模型的RL 模型的模型模型模拟一样, 整个RL 的模型 的模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 和 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 模型 的 模型 的 的 的 的 的 的 的 模型 的 模型 模型 模型 的 的 的 的 的 的 的 的 的 模型 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的