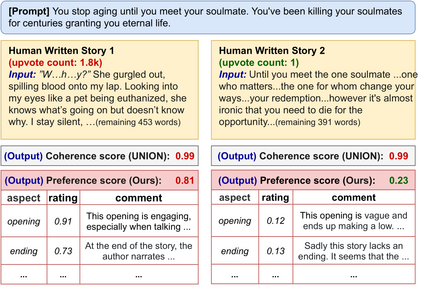
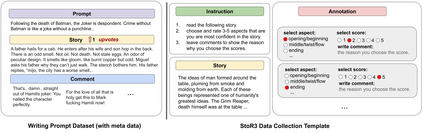
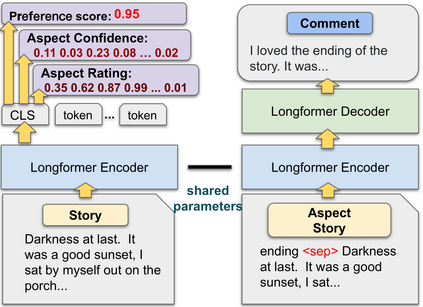
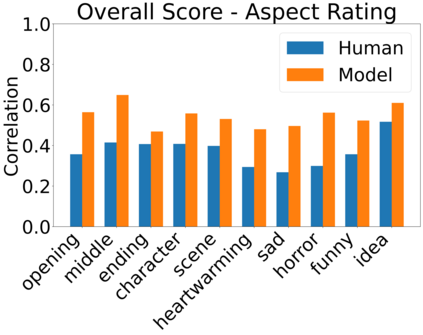
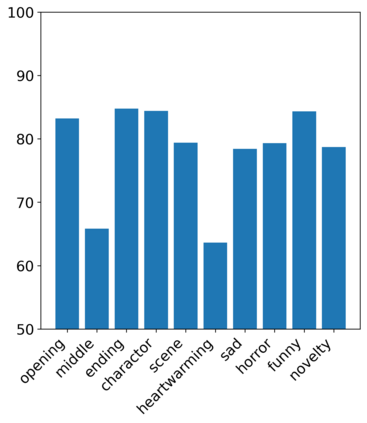
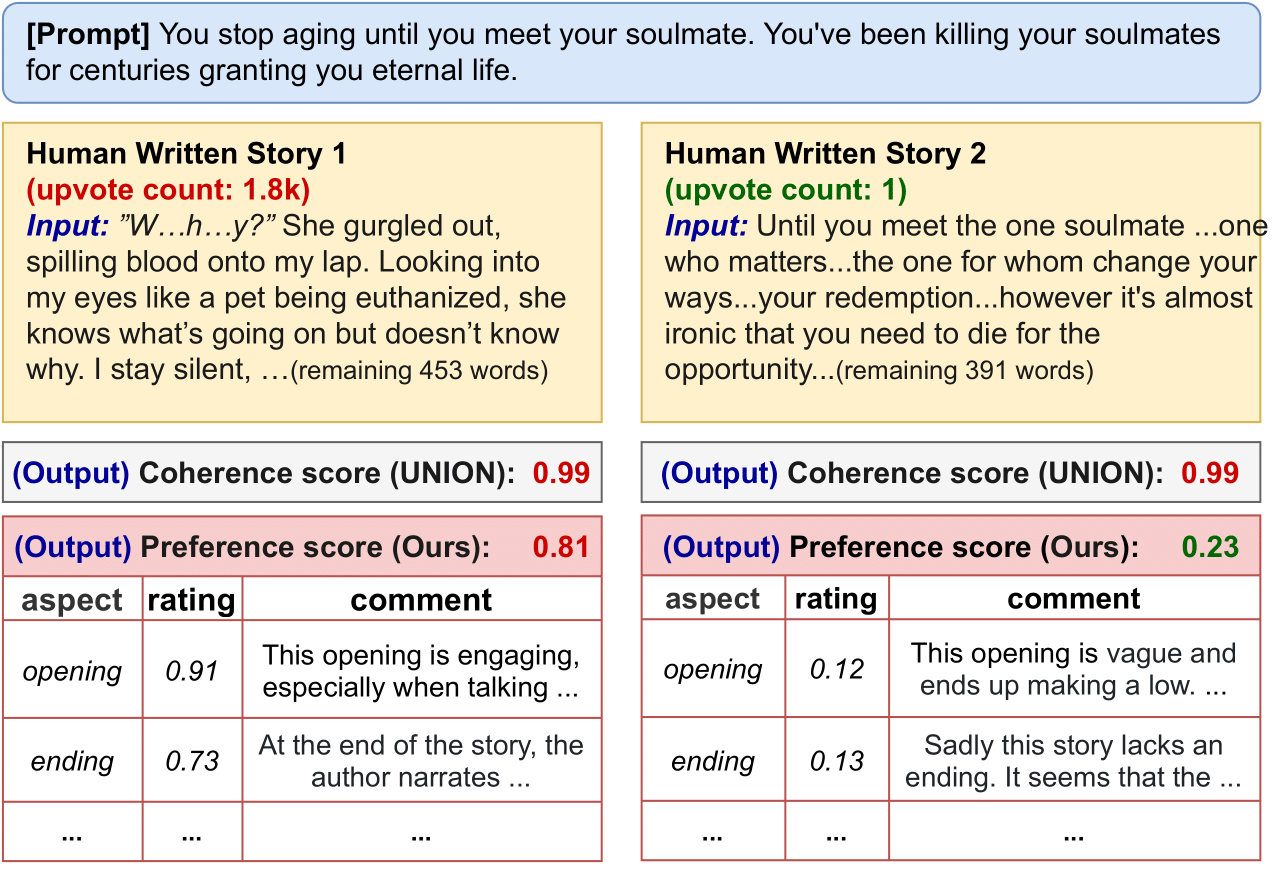
Existing automatic story evaluation methods place a premium on story lexical level coherence, deviating from human preference. We go beyond this limitation by considering a novel \textbf{Story} \textbf{E}valuation method that mimics human preference when judging a story, namely \textbf{StoryER}, which consists of three sub-tasks: \textbf{R}anking, \textbf{R}ating and \textbf{R}easoning. Given either a machine-generated or a human-written story, StoryER requires the machine to output 1) a preference score that corresponds to human preference, 2) specific ratings and their corresponding confidences and 3) comments for various aspects (e.g., opening, character-shaping). To support these tasks, we introduce a well-annotated dataset comprising (i) 100k ranked story pairs; and (ii) a set of 46k ratings and comments on various aspects of the story. We finetune Longformer-Encoder-Decoder (LED) on the collected dataset, with the encoder responsible for preference score and aspect prediction and the decoder for comment generation. Our comprehensive experiments result in a competitive benchmark for each task, showing the high correlation to human preference. In addition, we have witnessed the joint learning of the preference scores, the aspect ratings, and the comments brings gain in each single task. Our dataset and benchmarks are publicly available to advance the research of story evaluation tasks.\footnote{Dataset and pre-trained model demo are available at anonymous website \url{http://storytelling-lab.com/eval} and \url{https://github.com/sairin1202/StoryER}}
翻译:现有的自动故事评估方法 使故事120 水平的一致性受到重视, 与人类偏好脱节 。 我们超越了这一限制, 考虑一种新的\ textbf{ story}\ textbff{Storyf{E} 评估方法, 在判断故事时模仿人类的偏好, 即\ textbf{ storyER} 。 包括三个子任务 :\ textbf{ R} anking,\ textbf{ { textbf}{R}} 和\ textbf{R} http_ sonson 。 无论是从机器生成还是人写的故事, StoryER 需要机器到输出 1, 一种符合人类偏好、 2 特定评分及其相应的信任和 3 评论。 为了支持这些任务, 我们引入了一套46k 之前的评分和关于故事各个方面的评分。 我们对长期和 Encoder-Decer( LELED) 的评分, 在所收集的数据评分中, 将每个数据评分都显示了我们的历史评比值 。