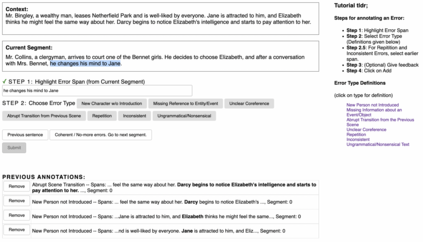
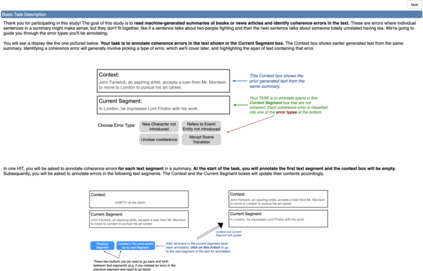
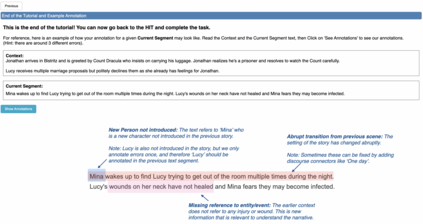
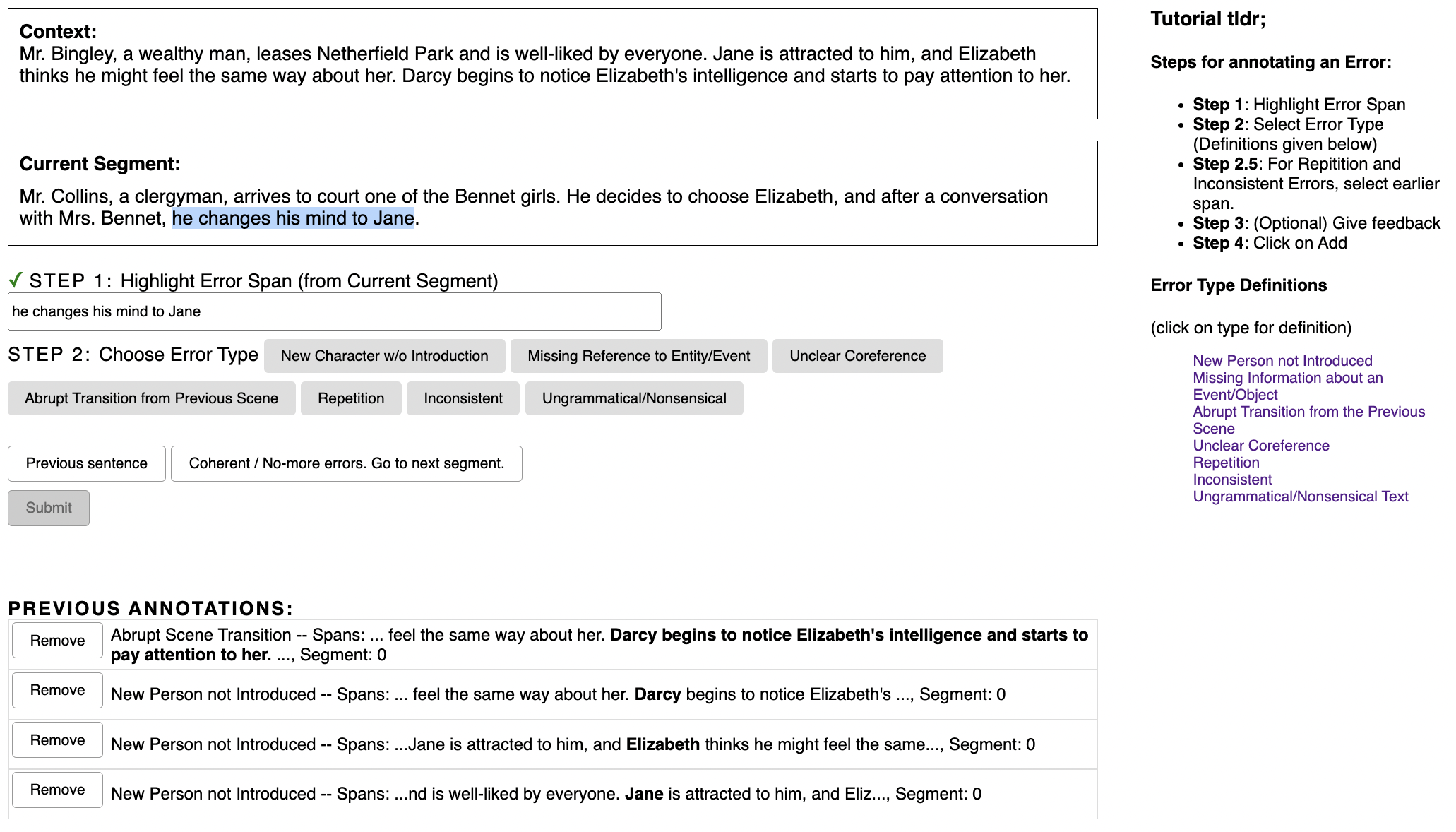
Progress in summarizing long texts is inhibited by the lack of appropriate evaluation frameworks. When a long summary must be produced to appropriately cover the facets of that text, that summary needs to present a coherent narrative to be understandable by a reader, but current automatic and human evaluation methods fail to identify gaps in coherence. In this work, we introduce SNaC, a narrative coherence evaluation framework rooted in fine-grained annotations for long summaries. We develop a taxonomy of coherence errors in generated narrative summaries and collect span-level annotations for 6.6k sentences across 150 book and movie screenplay summaries. Our work provides the first characterization of coherence errors generated by state-of-the-art summarization models and a protocol for eliciting coherence judgments from crowd annotators. Furthermore, we show that the collected annotations allow us to train a strong classifier for automatically localizing coherence errors in generated summaries as well as benchmarking past work in coherence modeling. Finally, our SNaC framework can support future work in long document summarization and coherence evaluation, including improved summarization modeling and post-hoc summary correction.
翻译:由于缺乏适当的评价框架,无法在总结长篇案文方面取得进展。当必须编写长篇摘要以适当涵盖该案文的各个方面时,该摘要需要提出一种连贯的说明,读者才能理解,但目前的自动和人文评价方法无法找出一致性方面的缺陷。在这项工作中,我们引入了SNAC, 这是一种叙述一致性评价框架,其根源在于细微的长篇说明;我们开发了生成的叙述性摘要中的一致性错误分类,收集了150本书和电影剧本摘要中6.6k句的跨层次说明。我们的工作首次描述了由最先进的总结模型产生的一致性错误,以及征求人群说明者作出一致性判断的程序。此外,我们表明,所收集的说明使我们能够培训强有力的分类人员,以便在生成的摘要中将一致性错误自动本地化,并将过去在一致性模型中的工作基准化。最后,我们的SNAC框架可以支持今后在长篇总结和一致性评价方面的工作,包括改进的总结模型和后摘要校正。