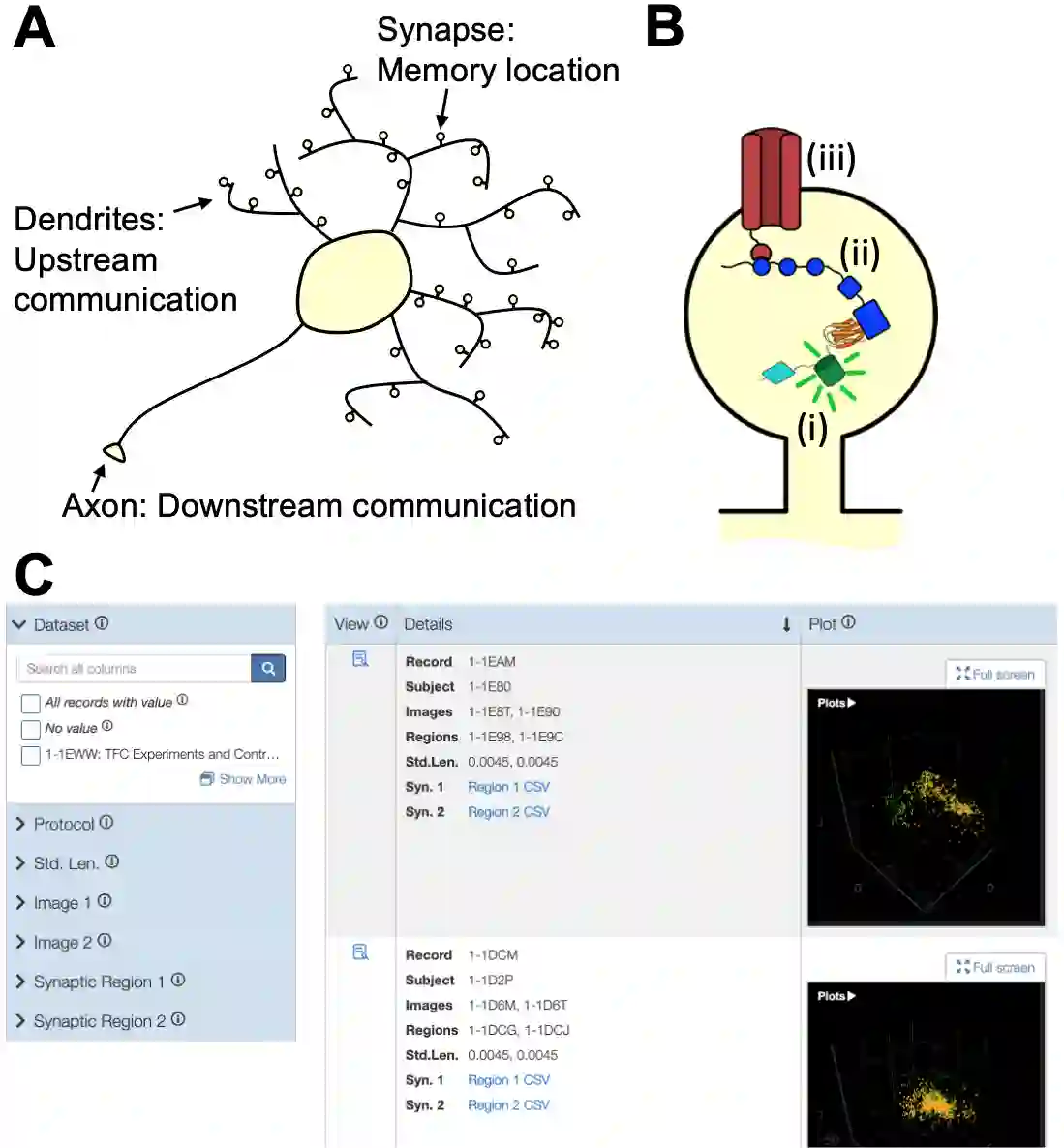
The broad sharing of research data is widely viewed as of critical importance for the speed, quality, accessibility, and integrity of science. Despite increasing efforts to encourage data sharing, both the quality of shared data, and the frequency of data reuse, remain stubbornly low. We argue here that a major reason for this unfortunate state of affairs is that the organization of research results in the findable, accessible, interoperable, and reusable (FAIR) form required for reuse is too often deferred to the end of a research project, when preparing publications, by which time essential details are no longer accessible. Thus, we propose an approach to research informatics that applies FAIR principles continuously, from the very inception of a research project, and ubiquitously, to every data asset produced by experiment or computation. We suggest that this seemingly challenging task can be made feasible by the adoption of simple tools, such as lightweight identifiers (to ensure that every data asset is findable), packaging methods (to facilitate understanding of data contents), data access methods, and metadata organization and structuring tools (to support schema development and evolution). We use an example from experimental neuroscience to illustrate how these methods can work in practice.
翻译:广泛分享研究数据被广泛视为对科学的速度、质量、可获取性和完整性至关重要。尽管人们日益努力鼓励数据共享,包括共享数据的质量和数据再利用的频率,但这种令人遗憾的状况的一个主要原因是,为再利用所需的可找到、可获取、可互操作和可再使用(FAIR)形式的研究成果的组织工作往往被推迟到研究项目的末尾,因为在编写出版物时,无法再获得必要的细节。因此,我们建议采用一种方法,从研究项目一开始,即普遍地将FAIR原则持续适用于试验或计算产生的每一个数据资产。我们建议,采用简单工具,例如轻量识别器(确保每个数据资产都可找到)、包装方法(便利对数据内容的理解)、数据获取方法、元组织和结构工具(支持系统开发和演进),可以使这一似乎具有挑战性的任务变得可行。我们用实验性神经科学的一个例子来说明这些方法如何在实践中发挥作用。