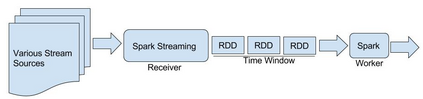
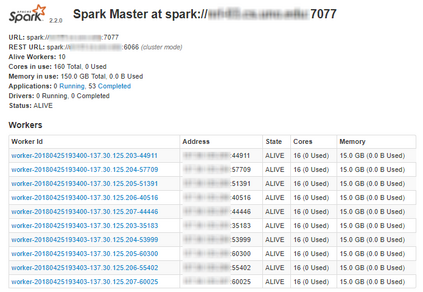
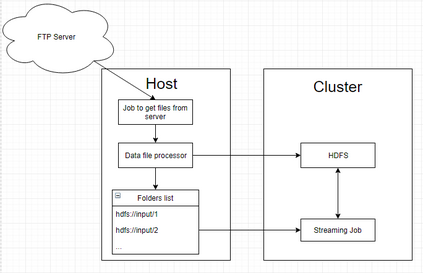
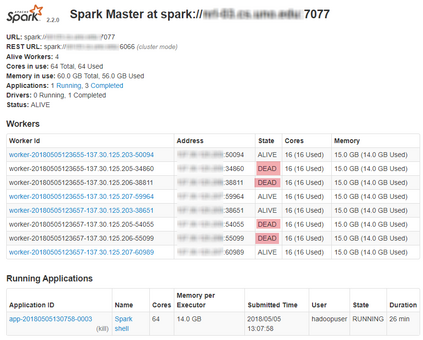
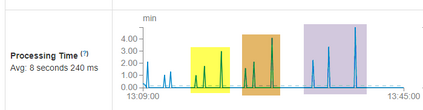
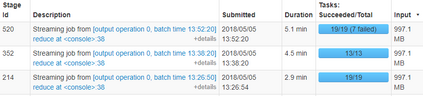
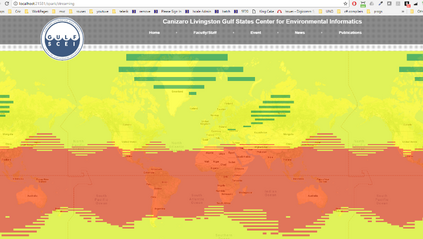
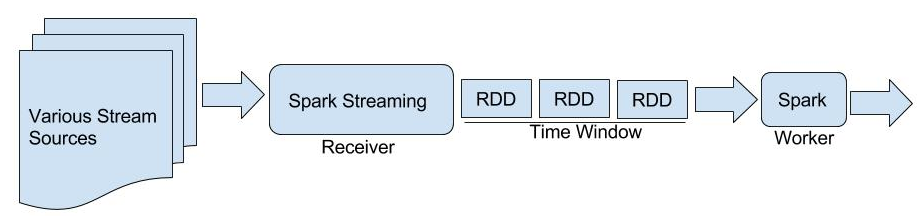
Real-world data from diverse domains require real-time scalable analysis. Large-scale data processing frameworks or engines such as Hadoop fall short when results are needed on-the-fly. Apache Spark's streaming library is increasingly becoming a popular choice as it can stream and analyze a significant amount of data. In this paper, we analyze large-scale geo-temporal data collected from the USGODAE (United States Global Ocean Data Assimilation Experiment) data catalog, and showcase and assess the ability of Spark stream processing. We measure the latency of streaming and monitor scalability by adding and removing nodes in the middle of a streaming job. We also verify the fault tolerance by stopping nodes in the middle of a job and making sure that the job is rescheduled and completed on other nodes. We design a full-stack application that automates data collection, data processing and visualizing the results. We also use Google Maps API to visualize results by color coding the world map with values from various analytics.
翻译:来自不同领域的现实世界数据需要实时可扩缩的分析。 大型数据处理框架或引擎,如Hadoop在需要实时结果时就不足了。 Apache Spark的流体图书馆在可以流出和分析大量数据时越来越成为流行的选择。 在本文中,我们分析从USGODAE(美国全球海洋数据模拟实验)数据目录中收集的大规模地理时空数据,并展示和评估Spark流流处理的能力。 我们通过在流出作业中添加和删除节点来衡量流和监测可扩缩的时空性。 我们还通过在工作中间停止节点,确保工作在其它节点上重新安排和完成来核查差错容忍度。 我们设计一个全套应用程序,将数据收集、数据处理和结果视觉化自动化。 我们还使用Google Maps API 来用各种分析器的数值对世界地图进行颜色编码,将结果进行视觉化。