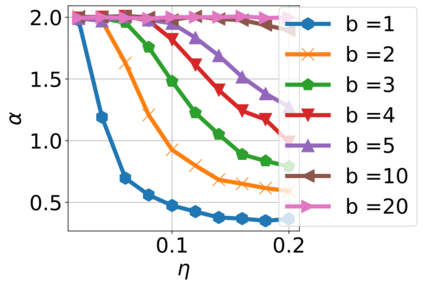
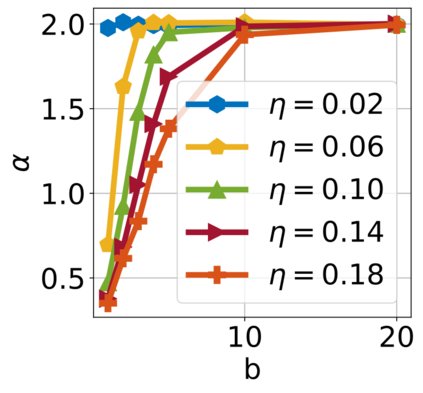
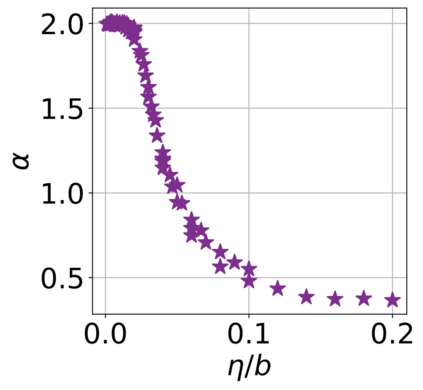
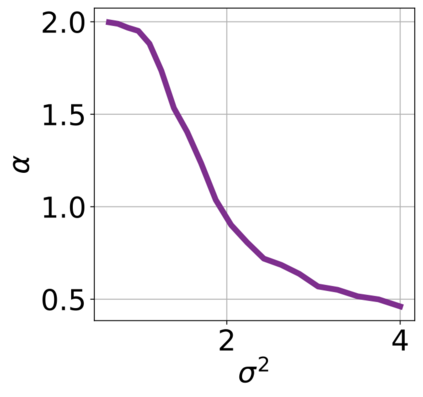
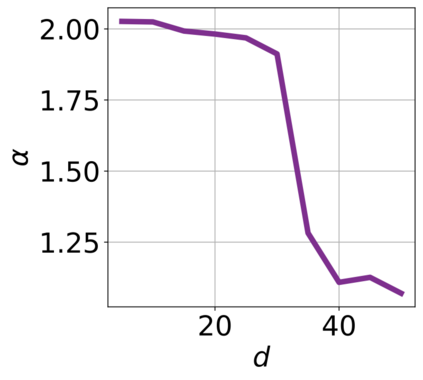
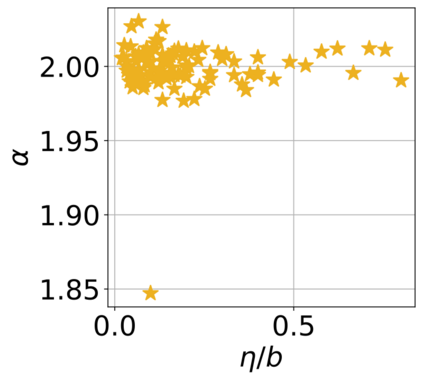
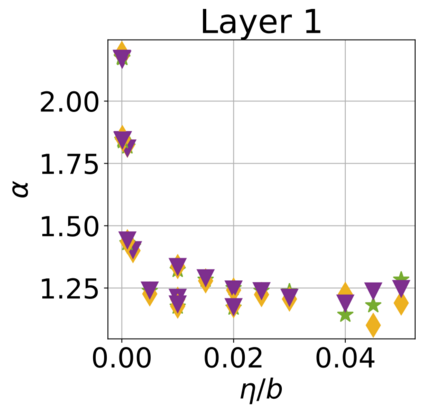
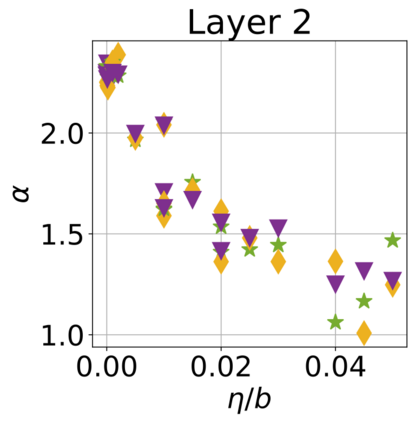
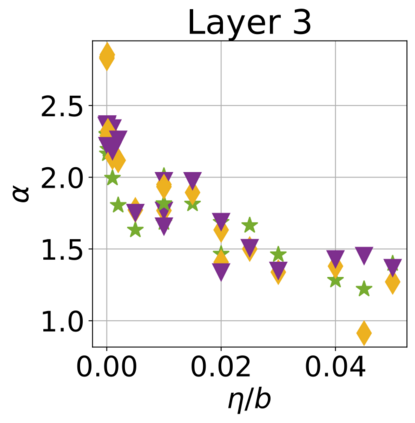
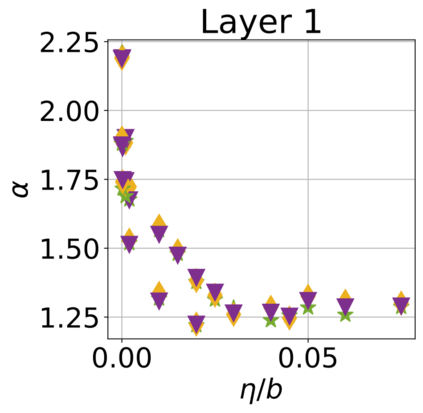
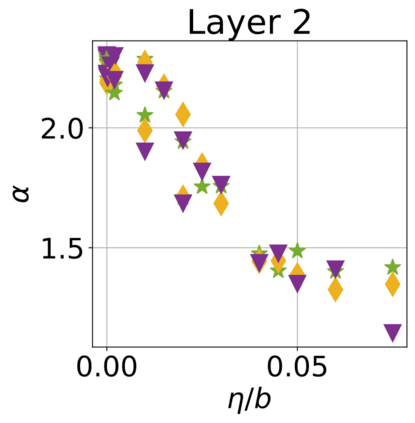
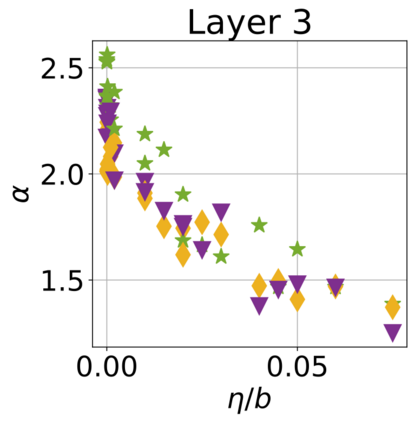
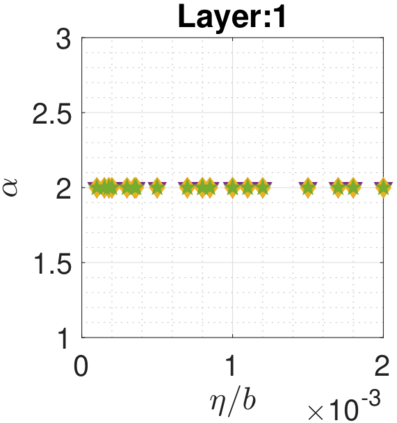
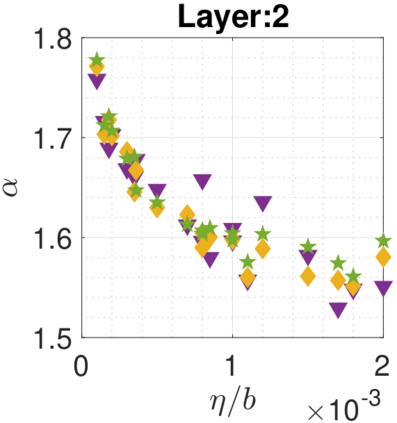
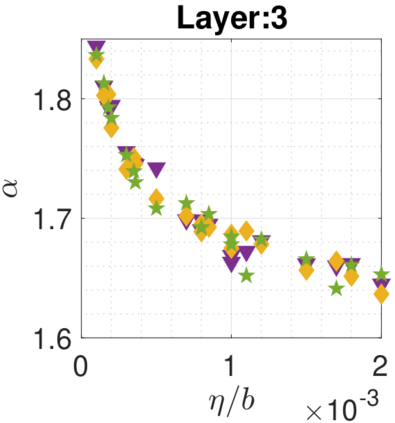
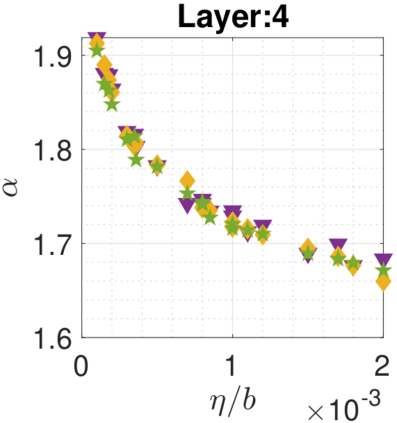
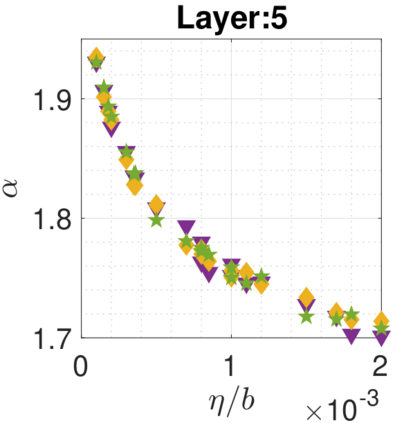
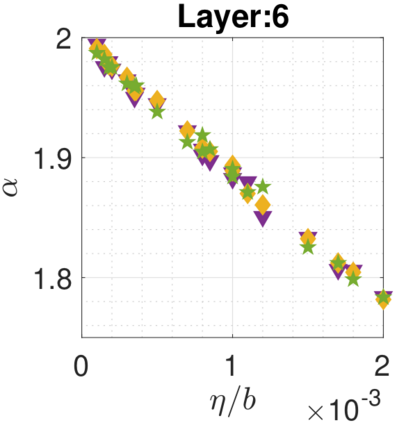
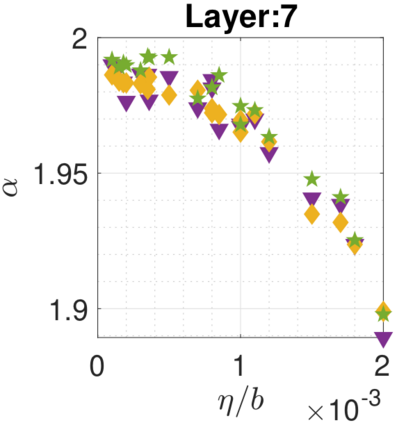
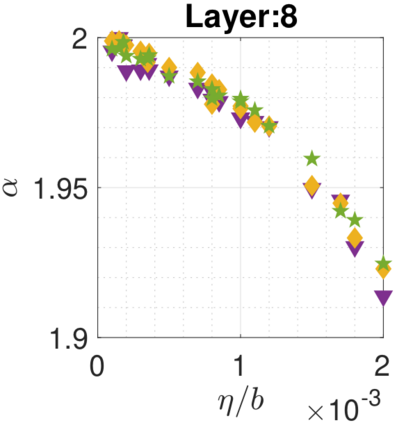
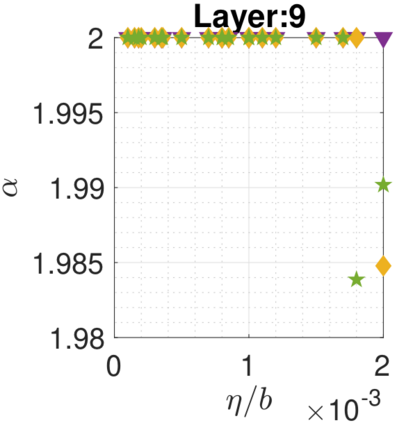
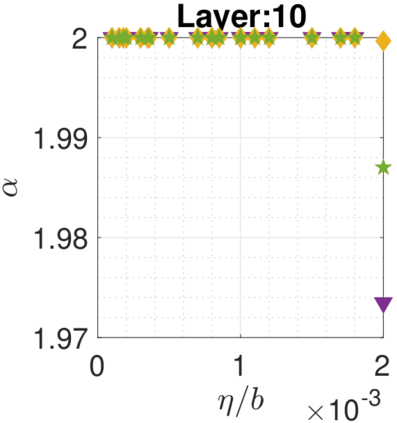
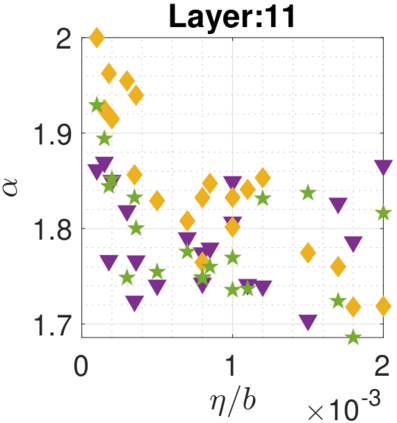
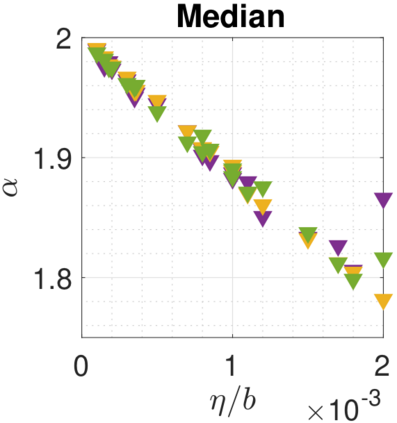
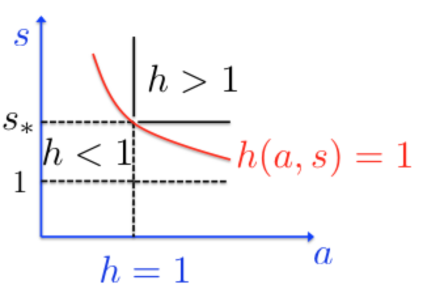
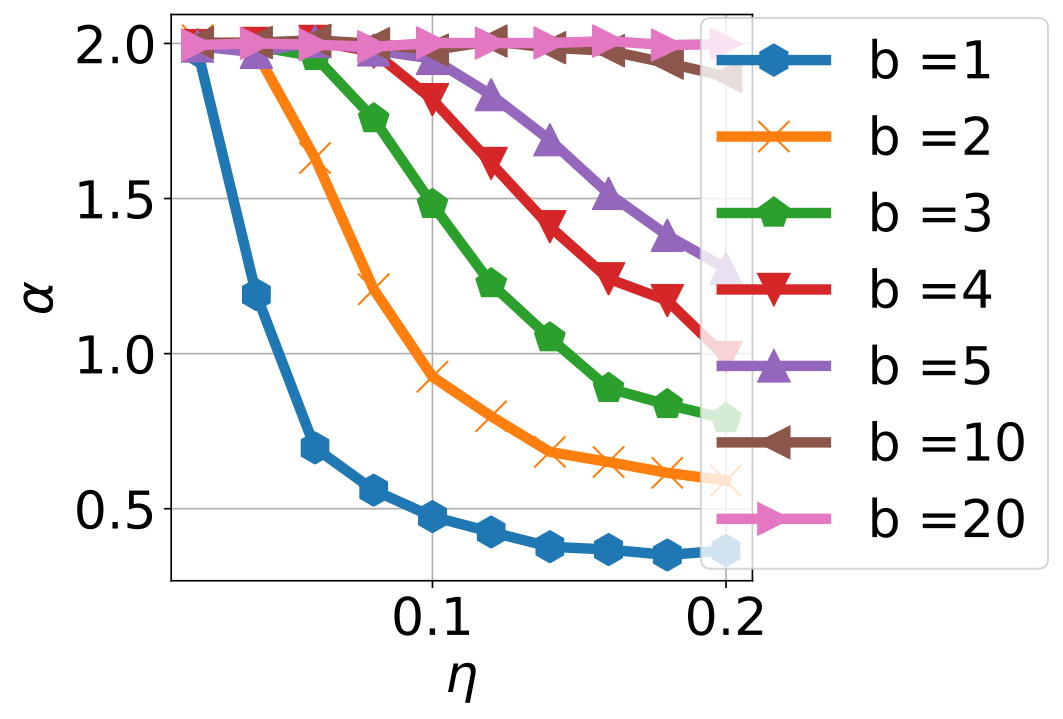
In recent years, various notions of capacity and complexity have been proposed for characterizing the generalization properties of stochastic gradient descent (SGD) in deep learning. Some of the popular notions that correlate well with the performance on unseen data are (i) the `flatness' of the local minimum found by SGD, which is related to the eigenvalues of the Hessian, (ii) the ratio of the stepsize $\eta$ to the batch-size $b$, which essentially controls the magnitude of the stochastic gradient noise, and (iii) the `tail-index', which measures the heaviness of the tails of the network weights at convergence. In this paper, we argue that these three seemingly unrelated perspectives for generalization are deeply linked to each other. We claim that depending on the structure of the Hessian of the loss at the minimum, and the choices of the algorithm parameters $\eta$ and $b$, the SGD iterates will converge to a \emph{heavy-tailed} stationary distribution. We rigorously prove this claim in the setting of quadratic optimization: we show that even in a simple linear regression problem with independent and identically distributed data whose distribution has finite moments of all order, the iterates can be heavy-tailed with infinite variance. We further characterize the behavior of the tails with respect to algorithm parameters, the dimension, and the curvature. We then translate our results into insights about the behavior of SGD in deep learning. We support our theory with experiments conducted on synthetic data, fully connected, and convolutional neural networks.
翻译:近些年来,在深层学习中,提出了各种能力和复杂性概念,以说明随机梯度下降(SGD)的一般特性。一些与隐蔽数据性能密切相关的流行概念是:(一) SGD发现的地方最低值的“增缩”,这与Hessian人的隐性价值有关,(二) 阶段的比值是美元与批量规模美元之间的比值,它基本上控制着随机梯度噪声的大小,以及(三) `尾端指数',它测量网络重量趋同时的尾部的高度性能。在本文件中,我们争辩说,SGD发现这三种似乎无关的当地最低值是彼此密切相关的。我们声称,取决于Hesian人最低限度的损失结构,以及算法参数的比值(美元和美元),SGD Itates的比值将进一步集中到一个正反偏斜度的弧度的曲线值值。我们更接近于网络的轨迹值,我们严格地证明了这个理论的变正值的演化过程, 其结构的变正变变变的变变变, 和变正的演化过程可以完全地显示我们所有的变形数据的变形的变形, 的变形的变形的变形的变形的变形过程的变形, 。