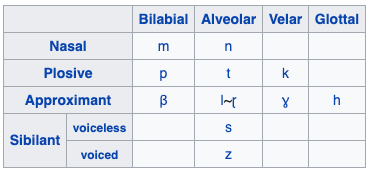
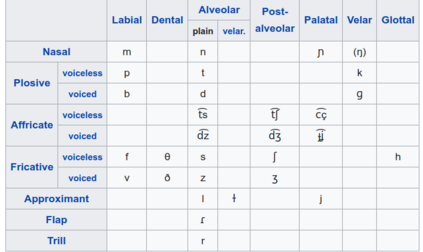
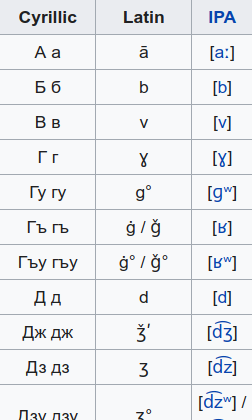
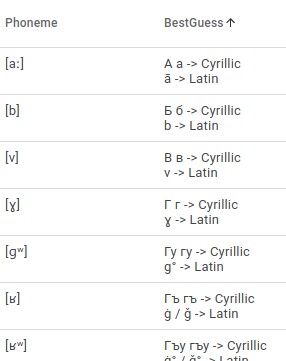
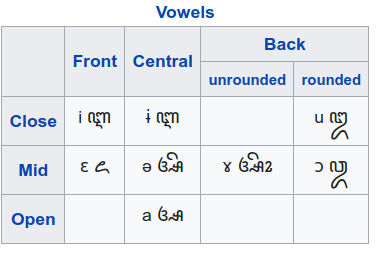
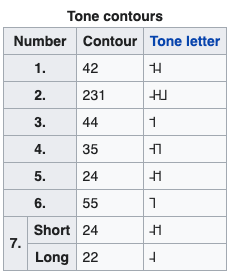
Pronunciation modeling is a key task for building speech technology in new languages, and while solid grapheme-to-phoneme (G2P) mapping systems exist, language coverage can stand to be improved. The information needed to build G2P models for many more languages can easily be found on Wikipedia, but unfortunately, it is stored in disparate formats. We report on a system we built to mine a pronunciation data set in 819 languages from loosely structured tables within Wikipedia. The data includes phoneme inventories, and for 63 low-resource languages, also includes the grapheme-to-phoneme (G2P) mapping. 54 of these languages do not have easily findable G2P mappings online otherwise. We turned the information from Wikipedia into a structured, machine-readable TSV format, and make the resulting data set publicly available so it can be improved further and used in a variety of applications involving low-resource languages.
翻译:发音模型是用新语言建立语音技术的一项关键任务,虽然有固态的图形化到手机(G2P)绘图系统,但语言覆盖面仍然有待改进。在维基百科上很容易找到为更多语言建立G2P模型所需的信息,但不幸的是,它以不同格式存储。我们报告了我们从维基百科内结构松散的表格中以819种语言建立的读音数据集储存的系统。这些数据包括电话清单和63种低资源语言的数据,还包括图形化到手机(G2P)的绘图。这些语言中,54种语言在网上不容易找到G2P绘图。我们把维基百科的信息转换成结构化的机器可读TSV格式,并向公众提供由此产生的数据集,以便进一步加以改进,用于涉及低资源语言的各种应用中。