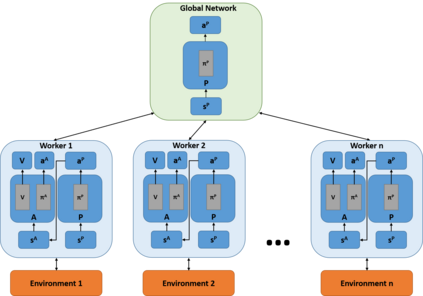
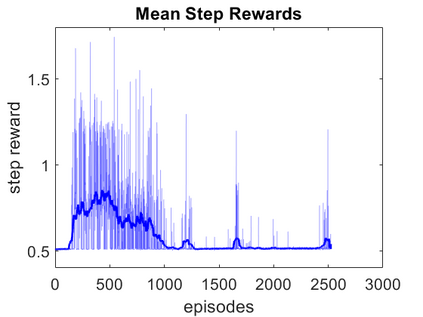
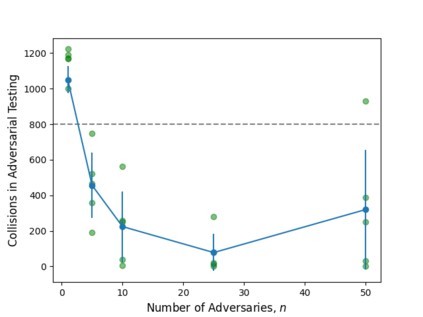
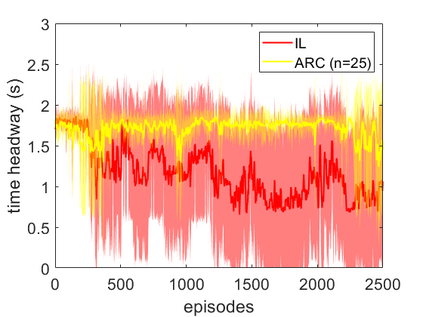
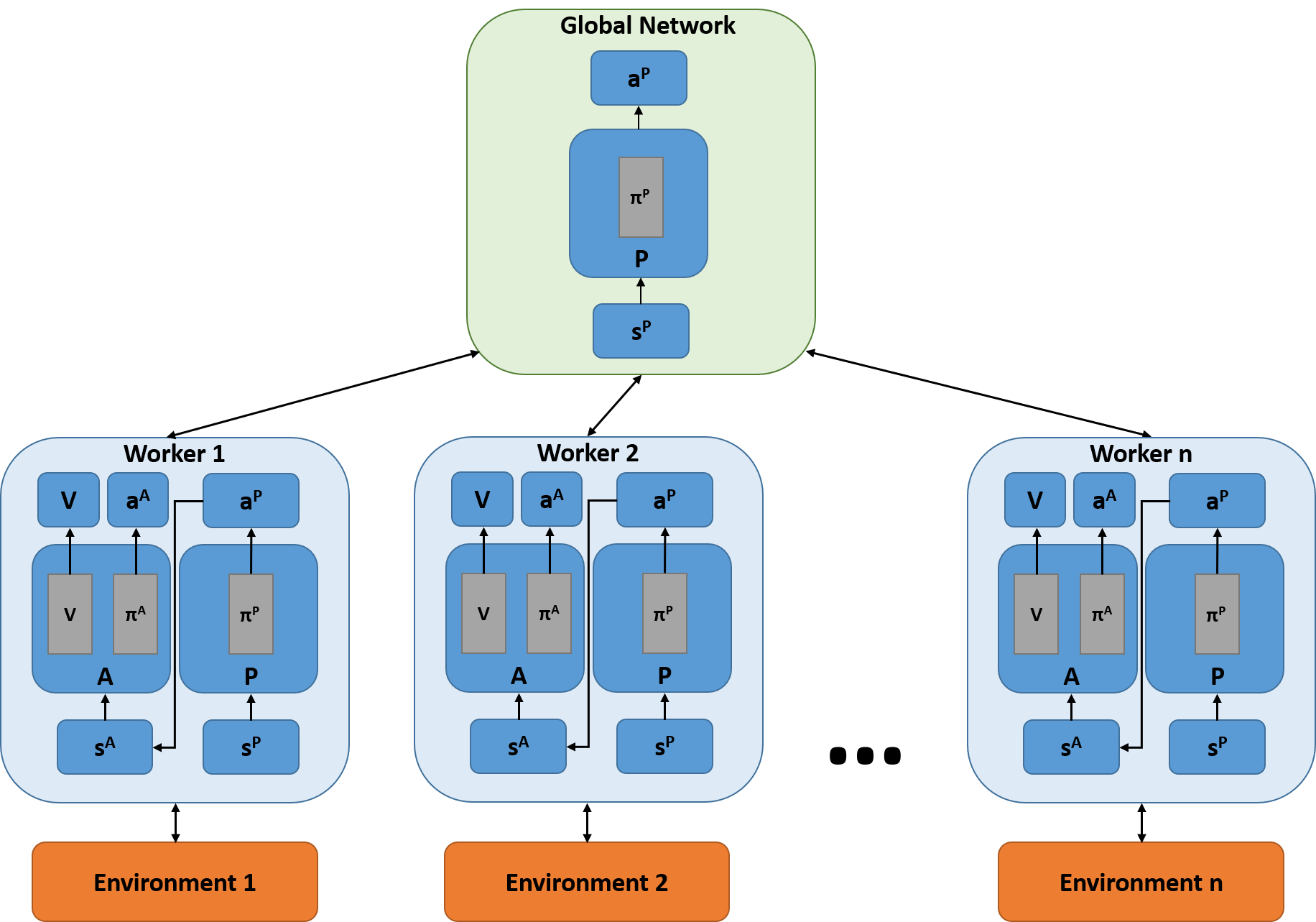
Deep neural networks have demonstrated their capability to learn control policies for a variety of tasks. However, these neural network-based policies have been shown to be susceptible to exploitation by adversarial agents. Therefore, there is a need to develop techniques to learn control policies that are robust against adversaries. We introduce Adversarially Robust Control (ARC), which trains the protagonist policy and the adversarial policy end-to-end on the same loss. The aim of the protagonist is to maximise this loss, whilst the adversary is attempting to minimise it. We demonstrate the proposed ARC training in a highway driving scenario, where the protagonist controls the follower vehicle whilst the adversary controls the lead vehicle. By training the protagonist against an ensemble of adversaries, it learns a significantly more robust control policy, which generalises to a variety of adversarial strategies. The approach is shown to reduce the amount of collisions against new adversaries by up to 90.25%, compared to the original policy. Moreover, by utilising an auxiliary distillation loss, we show that the fine-tuned control policy shows no drop in performance across its original training distribution.
翻译:深心神经网络展示了它们学习各种任务的控制政策的能力。然而,这些以神经网络为基础的政策已经证明很容易被对抗方代理人利用。因此,有必要开发各种技术来学习对对手的有力控制政策。我们引入了Aversarially 强力控制(ARC),该控制对主导政策和对同一损失的对抗政策端至端进行了培训。主角的目的是最大限度地减少这一损失,而对手则试图尽量减少这一损失。我们展示了拟议中的ARC培训在高速公路驱动情景下,由主角控制跟踪者车辆,而对手则控制主导车辆。通过培训对手,它学会了一种更加有力的控制政策,它概括了各种对抗战略。这种方法表明与最初的政策相比,对新对手的碰撞将减少90.25%。此外,通过使用辅助蒸馏损失,我们显示微调的控制政策没有在最初的培训分配中表现下降。