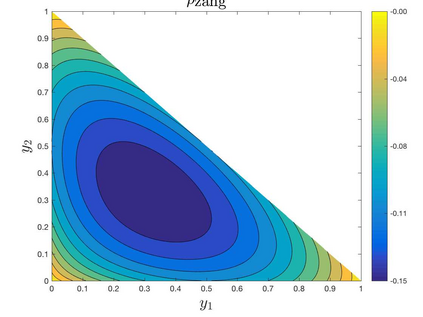
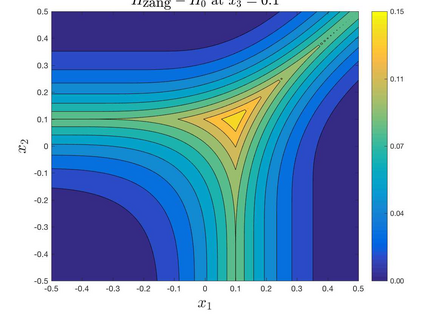
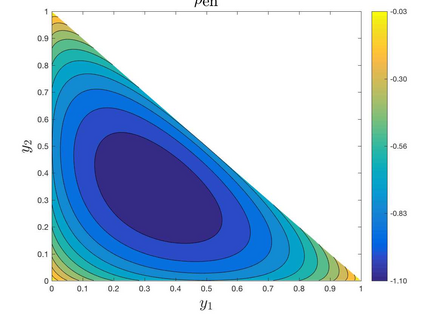
This paper proposes a relaxed control regularization with general exploration rewards to design robust feedback controls for multi-dimensional continuous-time stochastic exit time problems. We establish that the regularized control problem admits a H\"{o}lder continuous feedback control, and demonstrate that both the value function and the feedback control of the regularized control problem are Lipschitz stable with respect to parameter perturbations. Moreover, we show that a pre-computed feedback relaxed control has a robust performance in a perturbed system, and derive a first-order sensitivity equation for both the value function and optimal feedback relaxed control. These stability results provide a theoretical justification for recent reinforcement learning heuristics that including an exploration reward in the optimization objective leads to more robust decision making. We finally prove first-order monotone convergence of the value functions for relaxed control problems with vanishing exploration parameters, which subsequently enables us to construct the pure exploitation strategy of the original control problem based on the feedback relaxed controls.
翻译:本文建议放松控制规范, 并给予总体勘探奖励, 以设计对多维连续时间随机退出时间问题的强力反馈控制。 我们确定常规化控制问题认可了 H\"{o}lder 持续反馈控制, 并证明常规化控制问题的价值功能和反馈控制在参数扰动方面都是稳定的。 此外, 我们显示, 预先计算好的反馈放松控制在受扰动的系统中表现良好, 并且为价值功能和最佳反馈放松控制得出了一阶敏感度方程式。 这些稳定性结果为最近的强化学习偏重提供了理论依据, 包括优化目标中的勘探奖励导致更强有力的决策。 我们最终证明, 放松控制问题的价值功能与消失的勘探参数相匹配, 从而使我们能够根据反馈宽松控制建立原始控制问题的纯利用战略 。