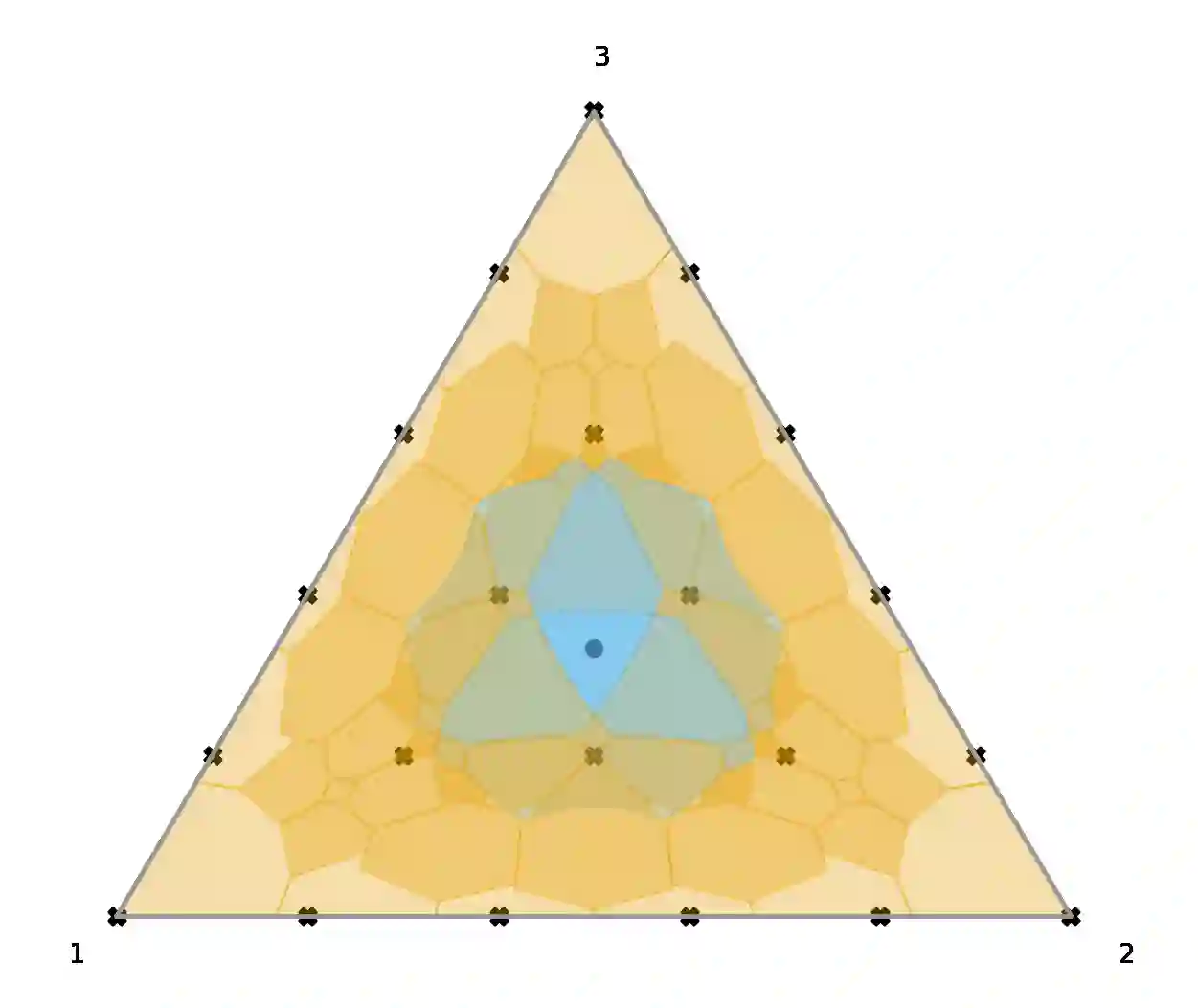
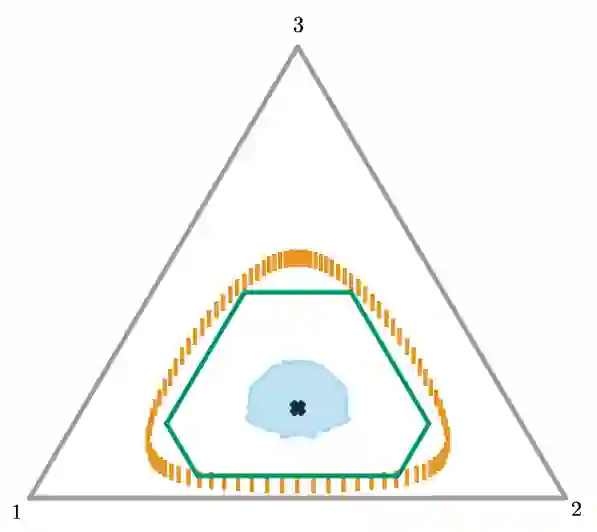
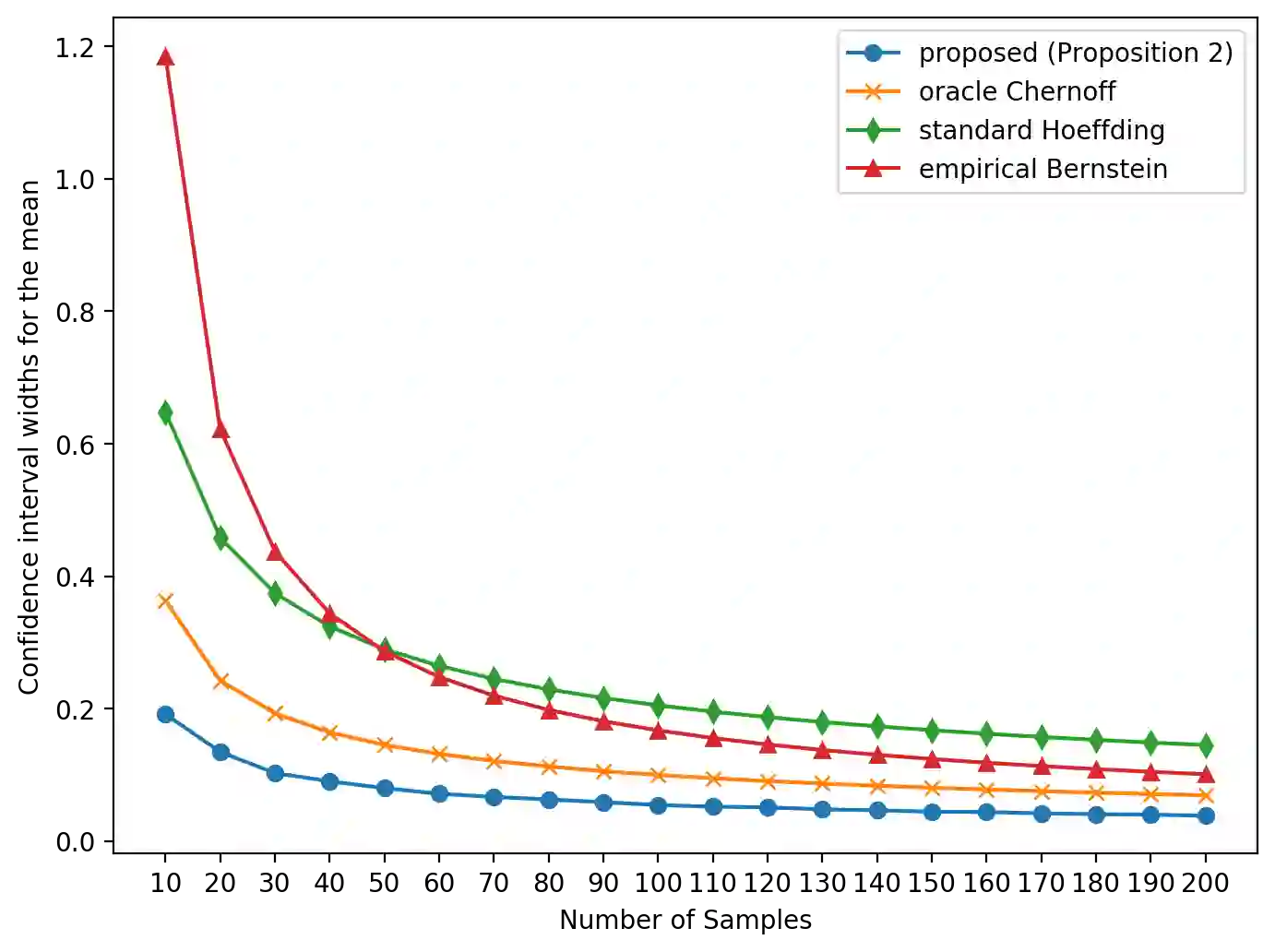
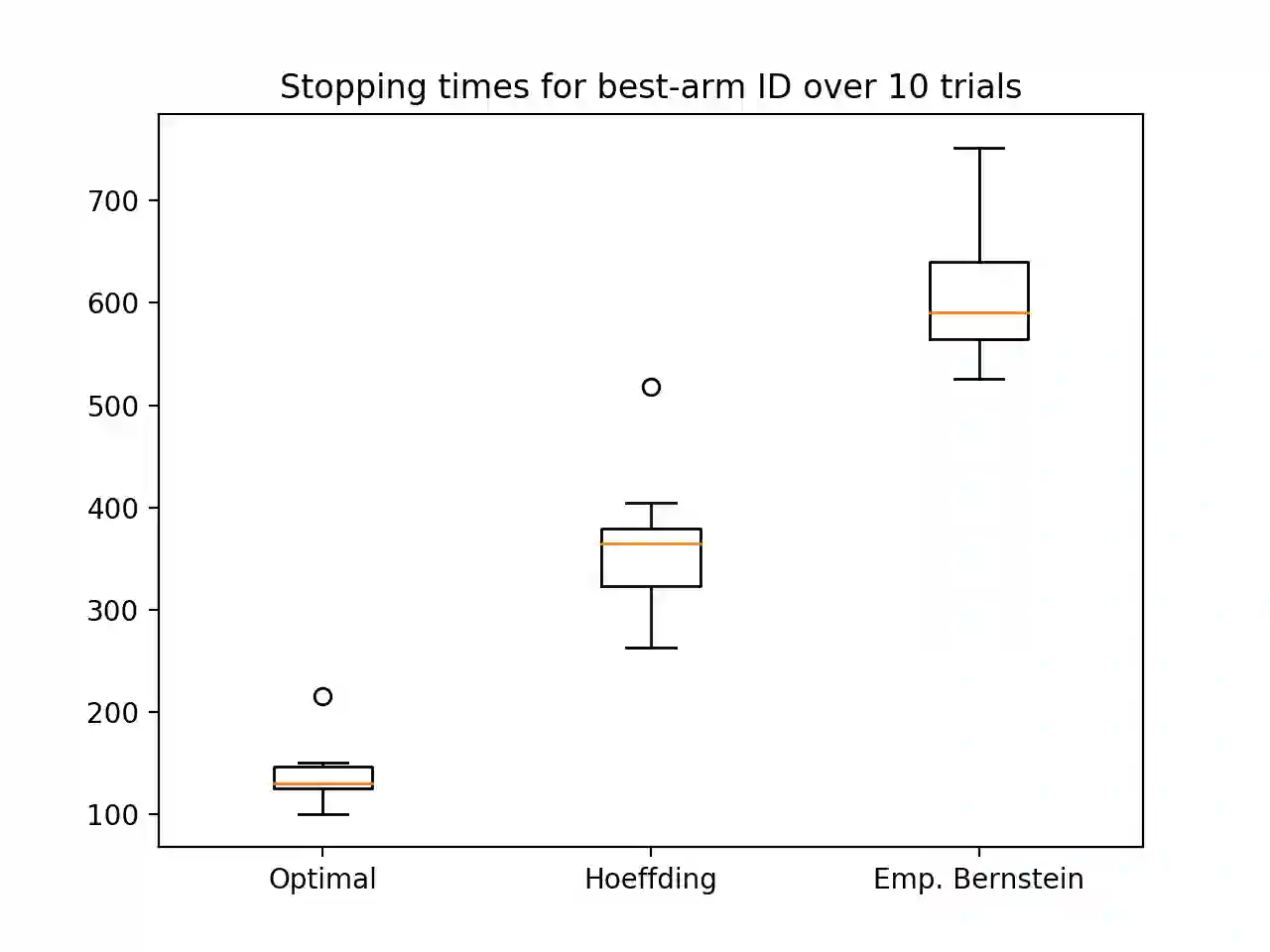
Construction of tight confidence regions and intervals is central to statistical inference and decision making. This paper develops new theory showing minimum average volume confidence regions for categorical data. More precisely, consider an empirical distribution $\widehat{\boldsymbol{p}}$ generated from $n$ iid realizations of a random variable that takes one of $k$ possible values according to an unknown distribution $\boldsymbol{p}$. This is analogous to a single draw from a multinomial distribution. A confidence region is a subset of the probability simplex that depends on $\widehat{\boldsymbol{p}}$ and contains the unknown $\boldsymbol{p}$ with a specified confidence. This paper shows how one can construct minimum average volume confidence regions, answering a long standing question. We also show the optimality of the regions directly translates to optimal confidence intervals of linear functionals such as the mean, implying sample complexity and regret improvements for adaptive machine learning algorithms.
翻译:构建紧信区和间隔是统计推论和决策的核心。 本文开发了新的理论, 显示绝对数据的最低平均数量信任区。 更准确地说, 考虑实证分配 $\ loberhat_ boldsymbol{ p ⁇ $ $ iid 实现一个随机变量产生的 $\ boldsymbol{ p $ 美元, 根据未知的分配 $\ boldsymbol{ p} $ 来计算一个可能值的 $k美元 。 这类似于从多元分布中提取的单数 。 信任区是概率简单x 的子集, 取决于 $\ 全域 hat_ boldsysymbol{ p } $, 含有未知的 $\ boldsysymsbol{ p} 美元, 并带有特定的信心。 本文展示了如何构建最小的平均数量信任区, 回答一个长期的问题。 我们还展示了区域的最佳性, 直接转换成线性功能的最佳信任度, 如平均值, 意味着适应机器学习算法的样本复杂度和遗憾改进。