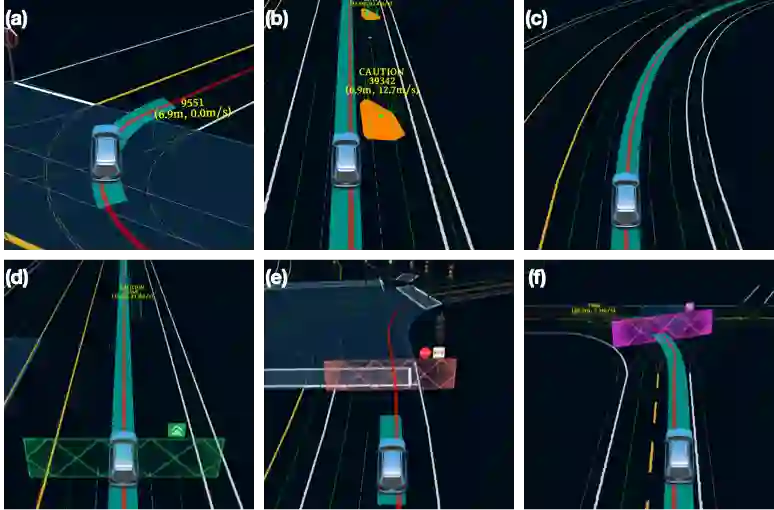
We present a learning-based planner that aims to robustly drive a vehicle by mimicking human drivers' driving behavior. We leverage a mid-to-mid approach that allows us to manipulate the input to our imitation learning network freely. With that in mind, we propose a novel feedback synthesizer for data augmentation. It allows our agent to gain more driving experience in various previously unseen environments that are likely to encounter, thus improving overall performance. This is in contrast to prior works that rely purely on random synthesizers. Furthermore, rather than completely commit to imitating, we introduce task losses that penalize undesirable behaviors, such as collision, off-road, and so on. Unlike prior works, this is done by introducing a differentiable vehicle rasterizer that directly converts the waypoints output by the network into images. This effectively avoids the usage of heavyweight ConvLSTM networks, therefore, yields a faster model inference time. About the network architecture, we exploit an attention mechanism that allows the network to reason critical objects in the scene and produce better interpretable attention heatmaps. To further enhance the safety and robustness of the network, we add an optional optimization-based post-processing planner improving the driving comfort. We comprehensively validate our method's effectiveness in different scenarios that are specifically created for evaluating self-driving vehicles. Results demonstrate that our learning-based planner achieves high intelligence and can handle complex situations. Detailed ablation and visualization analysis are included to further demonstrate each of our proposed modules' effectiveness in our method.
翻译:我们提出了一个基于学习的计划, 目的是通过模仿人类驾驶者的驾驶行为来强有力地驱动车辆。 我们利用中到中的方法, 使我们能够自由操作对模拟学习网络的输入。 考虑到这一点, 我们提出一个新的反馈合成器, 用于数据增强。 它让我们的代理商在各种可能遇到的先前不为人知的环境中获得更多的驾驶经验, 从而改善总体性能。 这与以前完全依赖随机合成器的工程形成对照。 此外, 我们不是完全致力于模仿, 而是引入任务损失, 惩罚不受欢迎的行为, 比如碰撞、 越轨等等。 与以前的工作不同, 这是通过引入一种不同的机动车呼吸器, 将网络的路径输出直接转换成图像。 这样可以有效地避免使用超重的 CONLSTM 网络, 从而产生一个更快的模型推导时间。 关于网络结构, 我们利用一个关注机制, 使得网络在现场对关键对象进行解释, 并产生更好的可解释的热调图。 为了进一步加强网络的安全和稳健度, 我们在网络中, 我们增加了一个可选择的驱动力分析方法, 具体地展示了我们的系统, 我们的自我分析, 我们的系统, 包括了一种选择性分析。 我们的模拟的系统, 我们的模拟, 我们的系统, 测试, 能够进一步地分析。