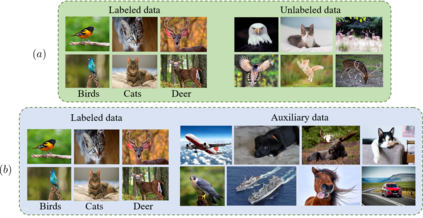
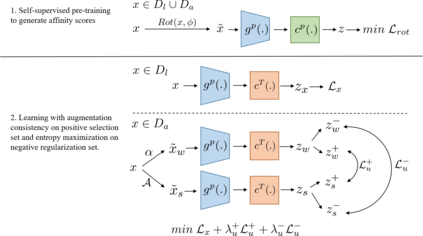
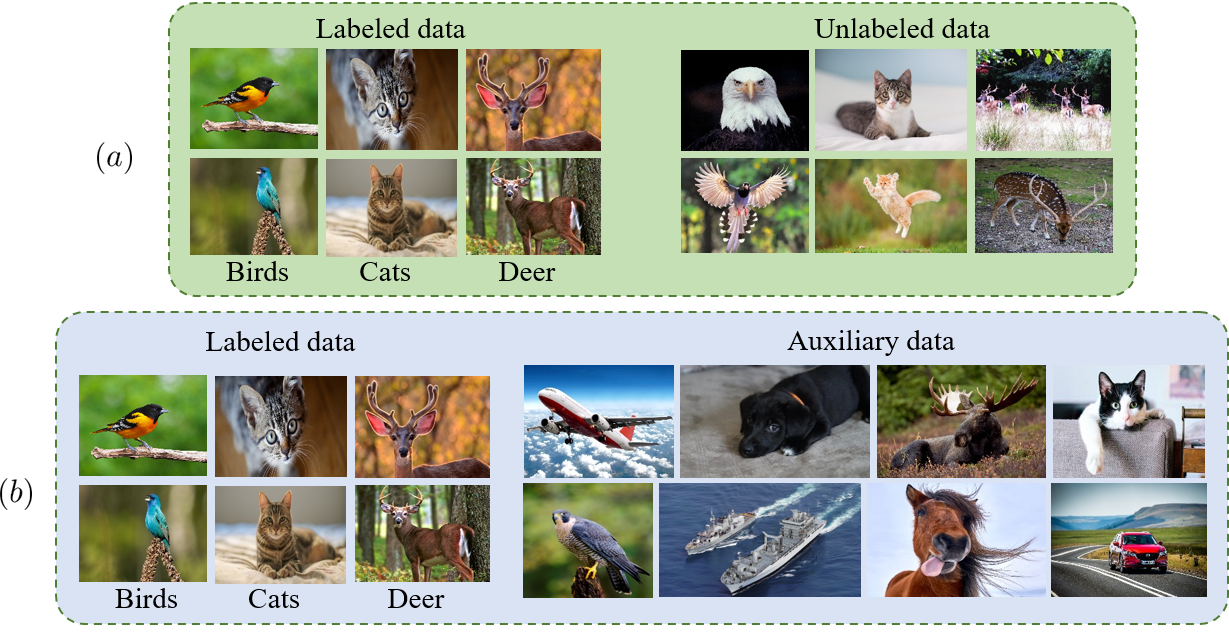
Semi-supervised learning (SSL) has seen great strides when labeled data is scarce but unlabeled data is abundant. Critically, most recent work assume that such unlabeled data is drawn from the same distribution as the labeled data. In this work, we show that state-of-the-art SSL algorithms suffer a degradation in performance in the presence of unlabeled auxiliary data that does not necessarily possess the same class distribution as the labeled set. We term this problem as Auxiliary-SSL and propose AuxMix, an algorithm that leverages self-supervised learning tasks to learn generic features in order to mask auxiliary data that are not semantically similar to the labeled set. We also propose to regularize learning by maximizing the predicted entropy for dissimilar auxiliary samples. We show an improvement of 5% over existing baselines on a ResNet-50 model when trained on CIFAR10 dataset with 4k labeled samples and all unlabeled data is drawn from the Tiny-ImageNet dataset. We report competitive results on several datasets and conduct ablation studies.
翻译:在标签数据稀少但没有标签的数据丰富的情况下,半监督的学习(SSL)取得了长足的进步。 关键是,最近的一项工作假设,这种未标签的数据来自与标签数据相同的分布。 在这项工作中,我们表明,在存在未标签的辅助数据的情况下,最先进的SSL算法在性能方面出现退化,这些数据不一定具有与标签数据集相同的等级分布。 我们把这个问题称为辅助性SSL, 并提议AuxMix, 这是一种利用自监督的学习任务来学习通用特性, 以掩盖与标签数据集不相类似的辅助数据。 我们还提议通过最大限度地利用预测的异类辅助样品的灵敏性来规范学习。 在用4k标签样本进行CIFAR10数据集培训时,我们展示了ResNet-50模型现有基线的5%的改进情况,而所有未标签数据都是从Tiny- Image Net数据集中提取的。 我们报告了若干数据集的竞争结果,并开展了防腐蚀研究。