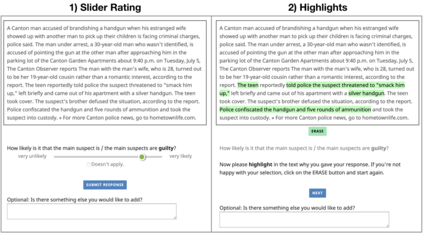
Crime reporting is a prevalent form of journalism with the power to shape public perceptions and social policies. How does the language of these reports act on readers? We seek to address this question with the SuspectGuilt Corpus of annotated crime stories from English-language newspapers in the U.S. For SuspectGuilt, annotators read short crime articles and provided text-level ratings concerning the guilt of the main suspect as well as span-level annotations indicating which parts of the story they felt most influenced their ratings. SuspectGuilt thus provides a rich picture of how linguistic choices affect subjective guilt judgments. In addition, we use SuspectGuilt to train and assess predictive models, and show that these models benefit from genre pretraining and joint supervision from the text-level ratings and span-level annotations. Such models might be used as tools for understanding the societal effects of crime reporting.
翻译:犯罪报道是一种普遍的新闻报道形式,有权塑造公众的看法和社会政策。 这些报告的语言如何影响读者? 我们试图与美国英语报纸的附加注释的犯罪故事嫌疑人Guilt Corpus 讨论这一问题。 对于嫌疑人Guilt, 告发员阅读了简短的犯罪文章,并提供了关于主要嫌疑人有罪情况的文本评级,以及跨层次的说明,说明他们认为故事中哪些部分对其评级影响最大。 疑犯Guilt 从而提供了丰富的语言选择如何影响主观有罪判决的图像。 此外,我们利用嫌疑人Guilt 来训练和评估预测模型,并表明这些模型受益于文本级别评级和跨层次说明的预培训和联合监督。这些模型可以用作理解犯罪报告的社会影响的工具。