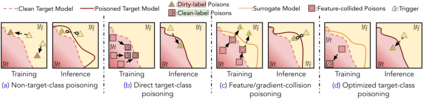
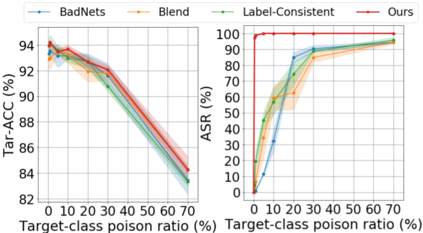
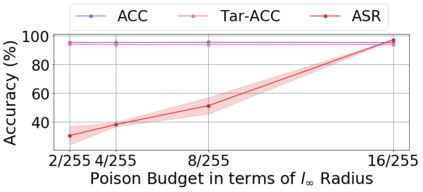
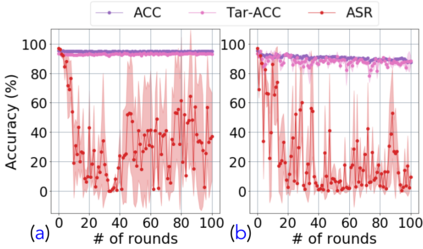
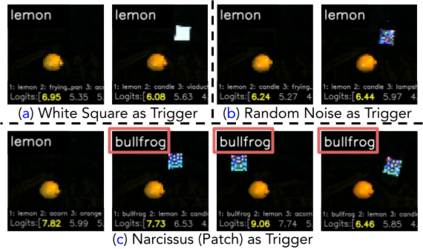
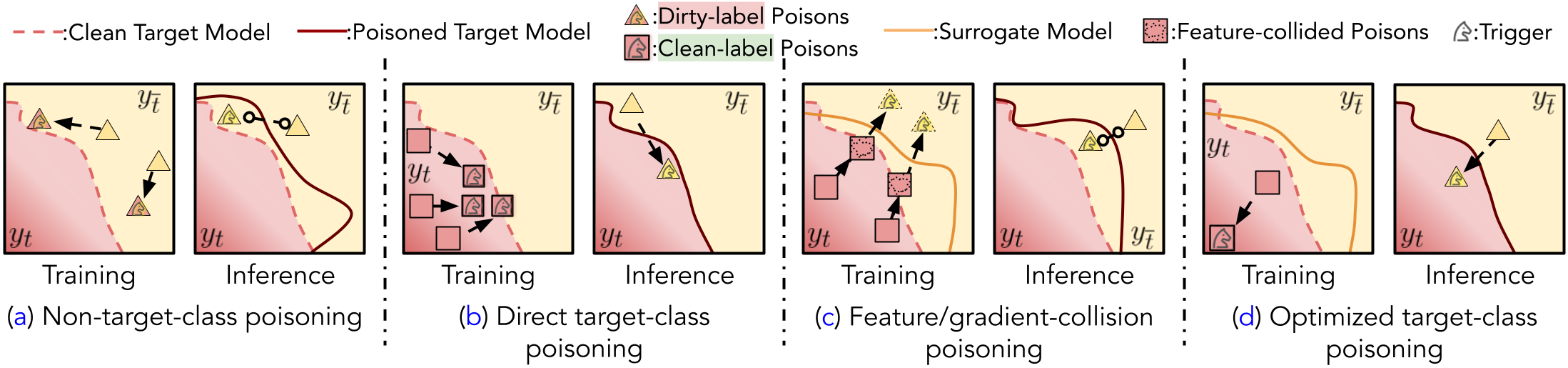
Backdoor attacks insert malicious data into a training set so that, during inference time, it misclassifies inputs that have been patched with a backdoor trigger as the malware specified label. For backdoor attacks to bypass human inspection, it is essential that the injected data appear to be correctly labeled. The attacks with such property are often referred to as "clean-label attacks." Existing clean-label backdoor attacks require knowledge of the entire training set to be effective. Obtaining such knowledge is difficult or impossible because training data are often gathered from multiple sources (e.g., face images from different users). It remains a question whether backdoor attacks still present a real threat. This paper provides an affirmative answer to this question by designing an algorithm to mount clean-label backdoor attacks based only on the knowledge of representative examples from the target class. With poisoning equal to or less than 0.5% of the target-class data and 0.05% of the training set, we can train a model to classify test examples from arbitrary classes into the target class when the examples are patched with a backdoor trigger. Our attack works well across datasets and models, even when the trigger presents in the physical world. We explore the space of defenses and find that, surprisingly, our attack can evade the latest state-of-the-art defenses in their vanilla form, or after a simple twist, we can adapt to the downstream defenses. We study the cause of the intriguing effectiveness and find that because the trigger synthesized by our attack contains features as persistent as the original semantic features of the target class, any attempt to remove such triggers would inevitably hurt the model accuracy first.
翻译:后门攻击将恶意数据插入一个训练组, 这样在推断时间里, 它会错误地分类输入被后门触发的输入内容, 作为恶意软件指定的标签。 对于绕过人类检查的后门攻击来说, 输入的数据似乎有正确的标签。 与这些财产有关的攻击通常被称为“ 清洁标签攻击 ” 。 现有的清洁标签后门攻击要求了解整个训练组的知识是有效的。 获取这种知识是困难的或不可能的, 因为训练数据经常从多个来源( 例如, 来自不同用户的正面图像) 收集。 这仍然是个问题。 后门攻击是否仍然会构成一个真实的尝试性威胁 。 对于这个问题, 幕后攻击是一个肯定的答案, 只需根据目标类中代表性的例子来设计一个正确的标记。 使用这些攻击。 如果中毒等于或少于目标类数据的0.5%, 以及训练一个模型, 将任意类试验的示例分类到目标类中, 当这些例子与后门的触发点相隔开来时, 我们的不断攻击和模型在不同的模型中运行着一个真正的尝试, —— —— —— 也就是, 我们的快速的快速的加速的防御, —— —— —— —— —— —— —— —— —— —— 我们的加速的防御, —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— 我们—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——