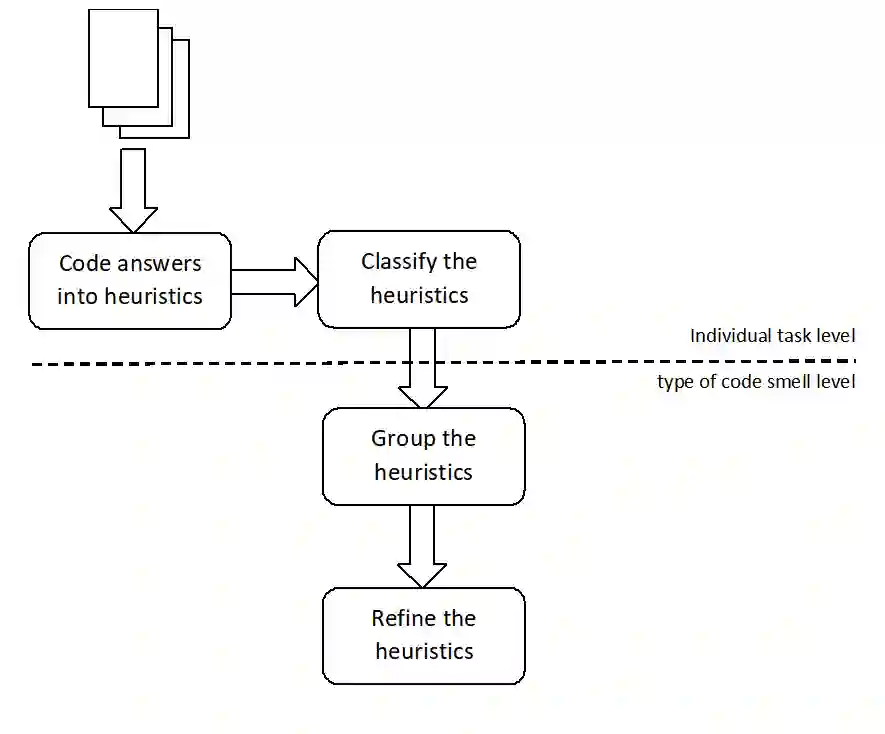
The identification of code smells is largely recognized as a subjective task. Consequently, the automated detection tools available are insufficient to deal with the whole subjectivity involved in the task, requiring human validation. However, developers may follow different but complementary perspectives for manually validating the same code smell. Based on this scenario, our research aims at characterizing a comprehensive and optimized set of heuristics for guiding developers to validate the incidence of code smells reported by automated detection tools. For this purpose, we conducted an empirical study with 12 experienced software developers. In this study, we invited developers to individually validate the incidence of code smells in 24 code snippets from open-source Java projects. For each validation, developers should provide arguments for supporting their decisions. The study findings revealed that developers tend to look from different perspectives even when they agree about the incidence of a code smell. After coding the 303 arguments given into heuristics and refining them, we composed an optimized set of validation items for guiding developers on manually validating the incidence of eight types of code smells: data class, god class, speculative generality, middle man, refused bequest, primitive obsession, long parameter list, and feature envy. We are currently planning a survey with specialists for identifying opportunities for evolving the set of validation items proposed.
翻译:因此,现有自动检测工具不足以应对任务所涉及的整个主观性,需要人类验证。然而,开发商可能遵循不同但互补的观点,手动验证同一代码的气味。基于这一假设,我们的研究旨在将一套全面、优化的螺旋体定性成一组,用于指导开发商验证自动检测工具报告的代码气味发生率。为此目的,我们与12个有经验的软件开发商进行了一项经验性研究。在这个研究中,我们邀请开发商单独验证开源爪哇项目24个代码片段中代码气味的发生率。对于每个验证,开发商应提供支持其决定的论据。研究结果显示,开发商往往从不同的角度审视,即使他们同意代码气味的发生率。在将303个参数编码编码编码编码编码的参数进行编码编码编码并对其进行完善后,我们为一套优化的验证项目组合,用于指导开发商手动验证8种代码气味的发生率:数据类、神类、投机性一般性、中继者、拒绝放弃的遗迹、原始性焦虑、长参数列表和特征验证专家。我们目前正在规划一项对不断变化的项目进行评估。