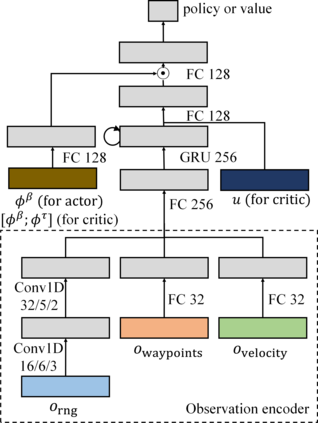
Modern navigation algorithms based on deep reinforcement learning (RL) show promising efficiency and robustness. However, most deep RL algorithms operate in a risk-neutral manner, making no special attempt to shield users from relatively rare but serious outcomes, even if such shielding might cause little loss of performance. Furthermore, such algorithms typically make no provisions to ensure safety in the presence of inaccuracies in the models on which they were trained, beyond adding a cost-of-collision and some domain randomization while training, in spite of the formidable complexity of the environments in which they operate. In this paper, we present a novel distributional RL algorithm that not only learns an uncertainty-aware policy, but can also change its risk measure without expensive fine-tuning or retraining. Our method shows superior performance and safety over baselines in partially-observed navigation tasks. We also demonstrate that agents trained using our method can adapt their policies to a wide range of risk measures at run-time.
翻译:基于深层强化学习(RL)的现代导航算法显示出很有希望的效率和稳健性。然而,大多数深层RL算法的运作方式都以风险中性的方式进行,没有特别试图保护用户免受相对少见但严重的结果的影响,即使这种屏蔽不会造成微小的性能损失。此外,这种算法通常没有规定在所培训的模型存在不准确的情况下确保安全,而除了在培训过程中增加调和成本和某些域随机化之外,在培训过程中,尽管他们所处的环境极为复杂。在本文件中,我们提出了一个新的分配式的RL算法,它不仅学习了认识不确定性的政策,而且还可以在不进行昂贵的微调或再培训的情况下改变其风险计量。我们的方法显示,在部分完成的导航任务中,在基线上表现优于业绩和安全。我们还表明,受过培训的代理人在使用我们的方法时可以调整其政策,使其适应在运行时采取的广泛风险措施。