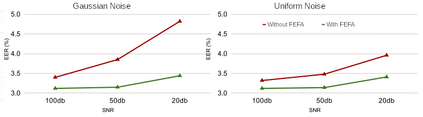
Attention mechanisms have emerged as important tools that boost the performance of deep models by allowing them to focus on key parts of learned embeddings. However, current attention mechanisms used in speaker recognition tasks fail to consider fine-grained information items such as frequency bins in input spectral representations used by the deep networks. To address this issue, we propose the novel Fine-grained Early Frequency Attention (FEFA) for speaker recognition in-the-wild. Once integrated into a deep neural network, our proposed mechanism works by obtaining queries from early layers of the network and generating learnable weights to attend to information items as small as the frequency bins in the input spectral representations. To evaluate the performance of FEFA, we use several well-known deep models as backbone networks and integrate our attention module in their pipelines. The overall performance of these networks (with and without FEFA) are evaluated on the VoxCeleb1 dataset, where we observe considerable improvements when FEFA is used.
翻译:为解决这一问题,我们提议采用新型精细早期注意(FEFA),供在远处的发言者识别。我们拟议机制一旦融入深层神经网络,就通过从网络早期层获得查询,产生可学习的重量,以照顾小于投入光谱显示器频率箱的信息项目。为了评估FEFA的性能,我们使用一些众所周知的深层模型作为主干网,并将我们的注意力模块纳入管道。这些网络的总体性能(与FEFA一起和不与FEFA一起)在VoxCeleb1数据集上进行了评估,我们发现在使用FEFA时,我们在VoxCeleb1数据集方面有相当大的改进。