
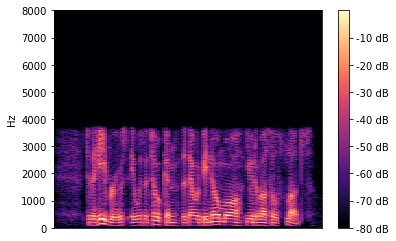
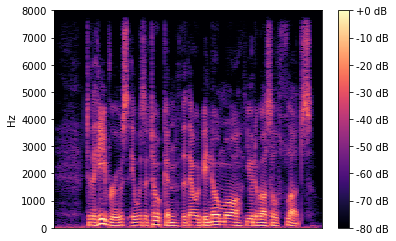
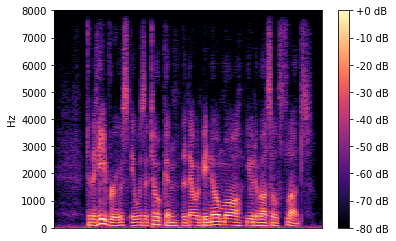
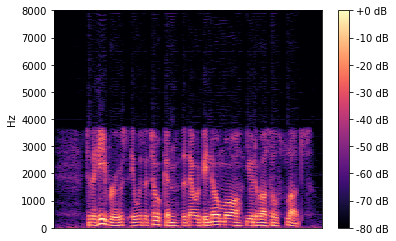
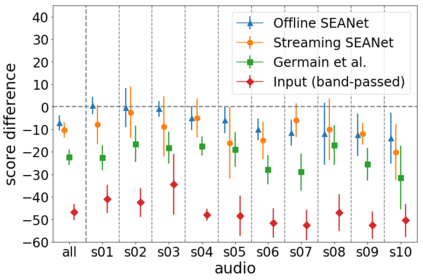
In this paper we propose a lightweight model for frequency bandwidth extension of speech signals, increasing the sampling frequency from 8kHz to 16kHz while restoring the high frequency content to a level almost indistinguishable from the 16kHz ground truth. The model architecture is based on SEANet (Sound EnhAncement Network), a wave-to-wave fully convolutional model, which uses a combination of feature losses and adversarial losses to reconstruct an enhanced version of the input speech. In addition, we propose a variant of SEANet that can be deployed on-device in streaming mode, achieving an architectural latency of 16ms. When profiled on a single core of a mobile CPU, processing one 16ms frame takes only 1.5ms. The low latency makes it viable for bi-directional voice communication systems.
翻译:在本文中,我们提出了语音信号频带宽扩展的轻量模型,将取样频率从8kHz提高到16kHz,同时将高频含量恢复到与16kHz地面真相几乎无法区分的水平。模型结构以SEANet(声频增强网络)为基础,这是一个波到波的全演化模型,它利用特征损失和对抗性损失的组合来重建输入演讲的强化版本。此外,我们提出了SEANet的变种,可以在流式设备上安装,达到16ms的建筑耐重。在对移动CPU的单个核心进行剖面时,处理1 16ms框架只需要1.5ms。低纬度使得双向语音通信系统可行。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


