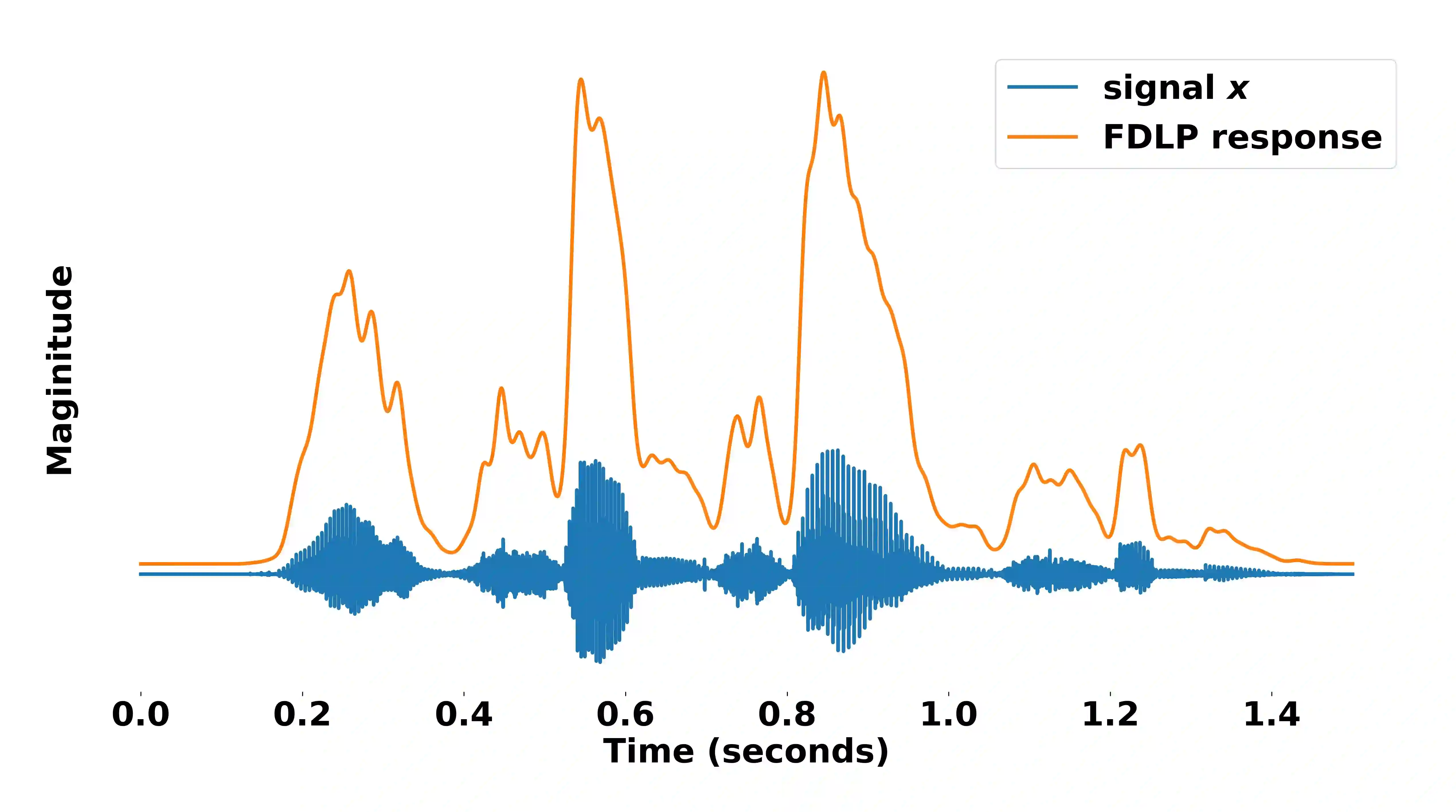
We propose a technique to compute spectrograms using Frequency Domain Linear Prediction (FDLP) that uses all-pole models to fit the squared Hilbert envelope of speech in different frequency sub-bands. The spectrogram of a complete speech utterance is computed by overlap-add of contiguous all-pole model responses. A long context window of 1.5 seconds allows us to capture the low frequency temporal modulations of speech in the spectrogram. For an end-to-end automatic speech recognition task, the FDLP spectrogram performs on par with the standard mel spectrogram features for clean read speech training and test data. For more realistic speech data with train-test domain mismatches or reverberations, FDLP spectrogram shows up to 25% and 22% relative WER improvements over mel spectrogram respectively.
翻译:我们建议使用频度内线性预测(DFLP)计算光谱技术,该技术使用全极模型来匹配不同频率子带的方格Hilbert语音信封。完整语音的光谱通过相重叠和相连全极模型响应来计算。1.5秒长的上下文窗口允许我们捕捉光光谱中低频时间调制的语音。为了完成端到端自动语音识别任务,FDLP光谱与标准的光谱特性相同,用于清洁读话培训和测试数据。对于更符合现实的语音数据,用火车测试域错配或反动计算,FDLP光谱显示在光谱上分别有25%和22%的相对WER改进。