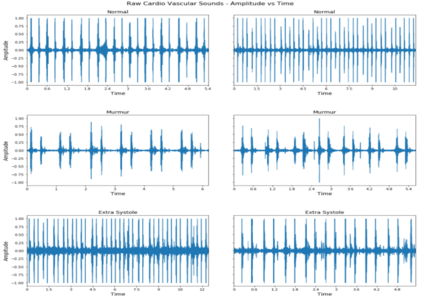
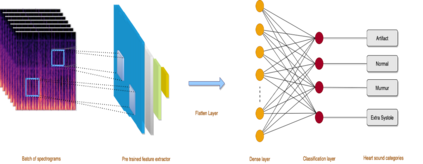
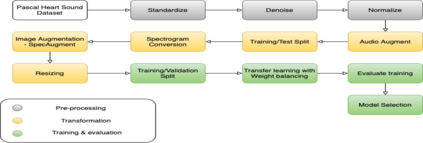
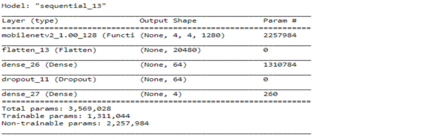
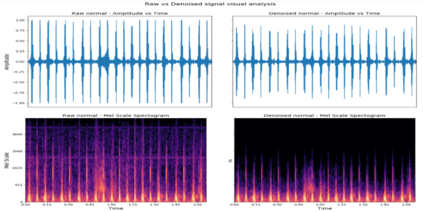
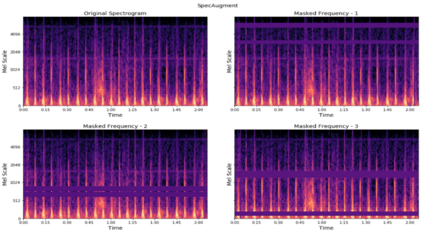
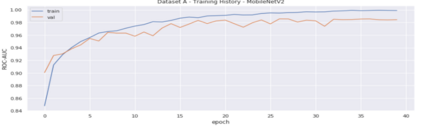
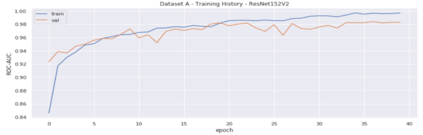
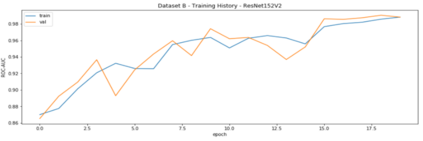
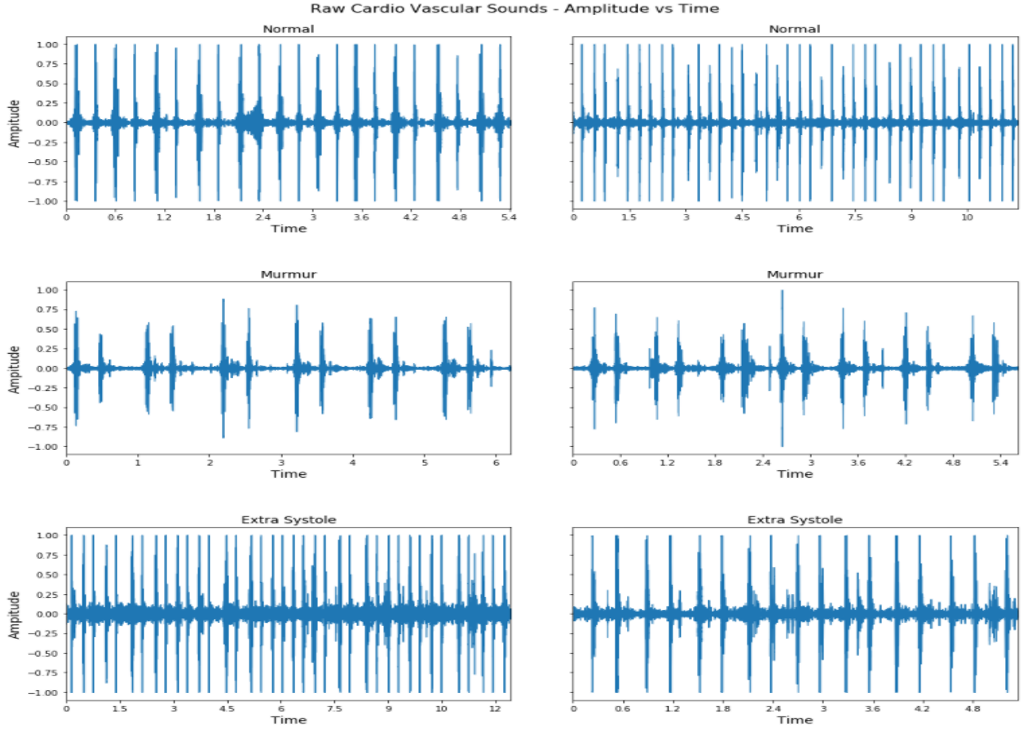
Heart disease is the most common reason for human mortality that causes almost one-third of deaths throughout the world. Detecting the disease early increases the chances of survival of the patient and there are several ways a sign of heart disease can be detected early. This research proposes to convert cleansed and normalized heart sound into visual mel scale spectrograms and then using visual domain transfer learning approaches to automatically extract features and categorize between heart sounds. Some of the previous studies found that the spectrogram of various types of heart sounds is visually distinguishable to human eyes, which motivated this study to experiment on visual domain classification approaches for automated heart sound classification. It will use convolution neural network-based architectures i.e. ResNet, MobileNetV2, etc as the automated feature extractors from spectrograms. These well-accepted models in the image domain showed to learn generalized feature representations of cardiac sounds collected from different environments with varying amplitude and noise levels. Model evaluation criteria used were categorical accuracy, precision, recall, and AUROC as the chosen dataset is unbalanced. The proposed approach has been implemented on datasets A and B of the PASCAL heart sound collection and resulted in ~ 90% categorical accuracy and AUROC of ~0.97 for both sets.
翻译:早期检测该疾病增加了病人存活的机会,并且有几种方法可以早期检测到心脏病的症状。该研究提议将经过清洗和正常化的心脏声音转换成视觉中子比例谱谱仪,然后使用视觉域传输学习方法,以自动提取特征和对心脏声音进行分类。先前的一些研究发现,各种类型心脏声音的光谱在人类眼中可以辨别,这促使本项研究实验用于自动心脏声音分类的视觉域分类方法。它将使用以神经网络为基础的神经结构,即ResNet、MiveNetV2等,作为光谱仪的自动特征提取器。这些在图像领域的公认模型显示,可以了解不同环境中收集的心脏声音的通用特征表现,而不同环境的振幅和噪音程度各不相同。使用的模型评价标准是绝对准确性、精确性、回顾和AUROC,因为所选的数据集是不平衡的。拟议方法已经用于用于A型和B型神经网络结构,即神经网络结构,例如ResNet、MobilNetV2, 等,作为光谱中的自动特征提取器。这些模型显示,用于收集的绝对值为90-UR 声音数据集。