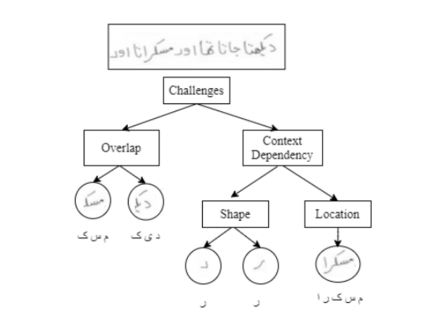
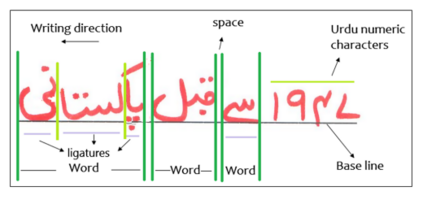
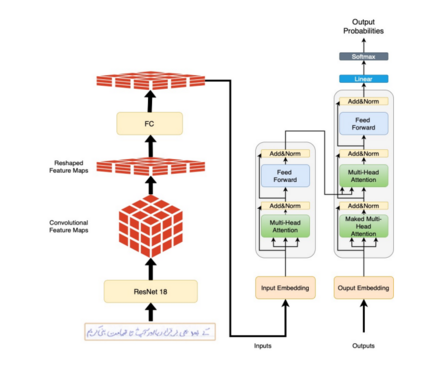
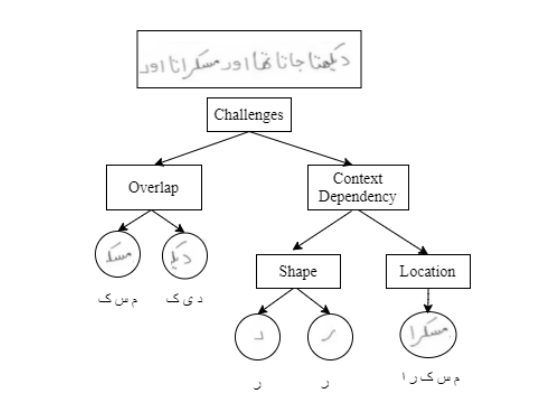
Extracting Handwritten text is one of the most important components of digitizing information and making it available for large scale setting. Handwriting Optical Character Reader (OCR) is a research problem in computer vision and natural language processing computing, and a lot of work has been done for English, but unfortunately, very little work has been done for low resourced languages such as Urdu. Urdu language script is very difficult because of its cursive nature and change of shape of characters based on it's relative position, therefore, a need arises to propose a model which can understand complex features and generalize it for every kind of handwriting style. In this work, we propose a transformer based Urdu Handwritten text extraction model. As transformers have been very successful in Natural Language Understanding task, we explore them further to understand complex Urdu Handwriting.
翻译:手写文本的提取是信息数字化和大规模设置信息的最重要组成部分之一。手写光学字符阅读器(OCR)是计算机视觉和自然语言处理计算方面的一个研究问题,对英语已经做了大量工作,但不幸的是,对于诸如乌尔都语等资源不足的语言,工作很少。乌尔都语文字非常困难,因为其翻译性质和基于相对位置的字符形状变化,因此,需要提出一个能够理解复杂特征和对各种笔迹风格加以概括的模型。在这项工作中,我们提出了一个基于乌尔都手写文本提取模型的变压器。由于变压器在自然语言理解任务中非常成功,我们进一步探索这些变压器以理解复杂的乌尔都手写。