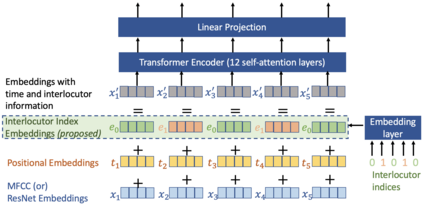
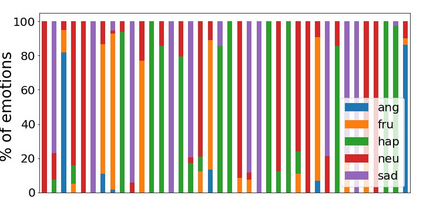
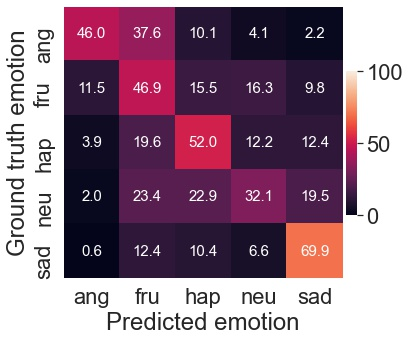
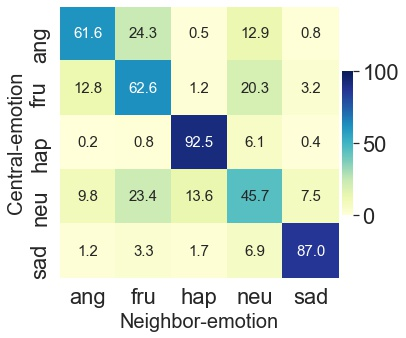
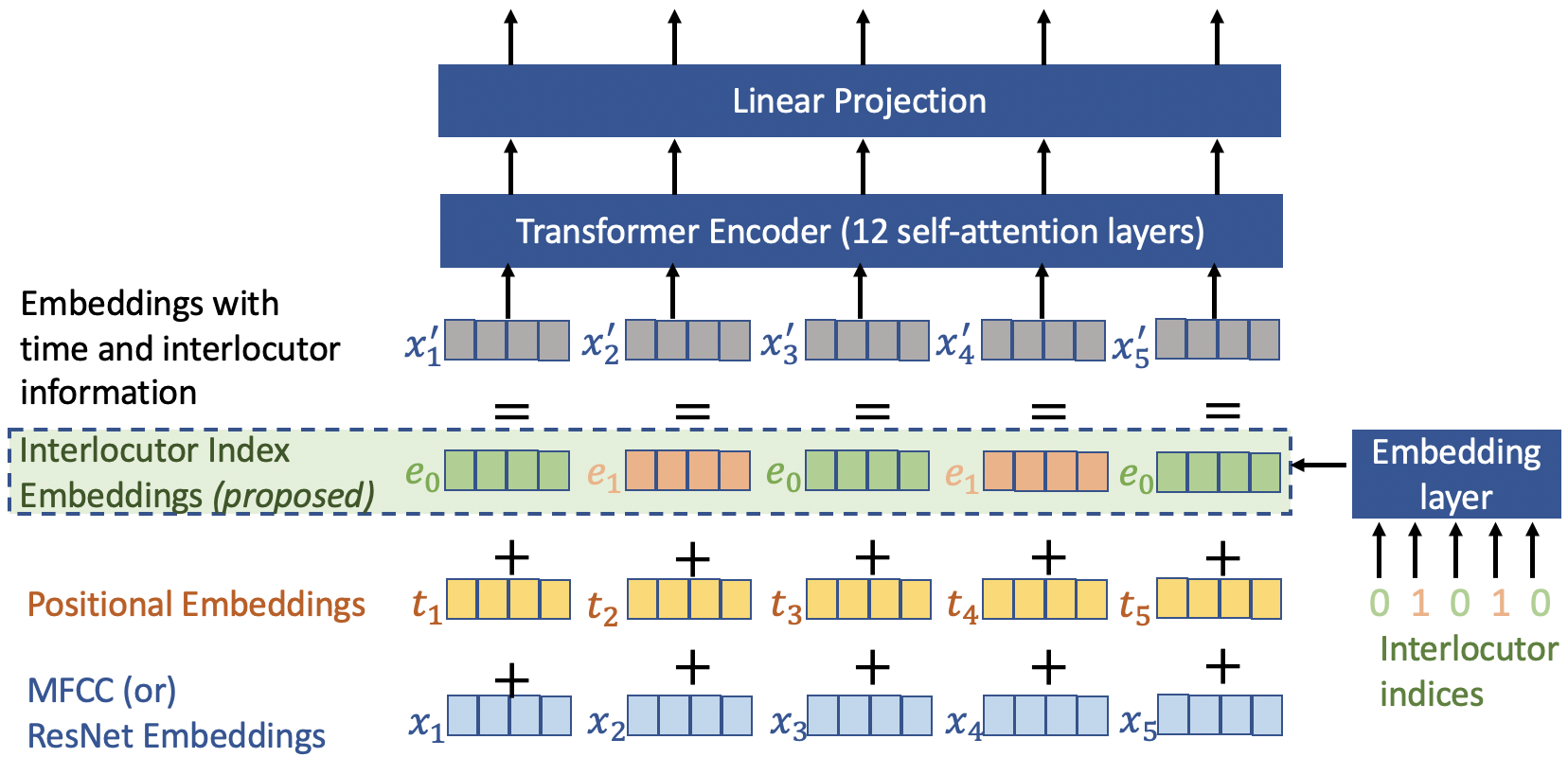
Speech emotion recognition is the task of recognizing the speaker's emotional state given a recording of their utterance. While most of the current approaches focus on inferring emotion from isolated utterances, we argue that this is not sufficient to achieve conversational emotion recognition (CER) which deals with recognizing emotions in conversations. In this work, we propose several approaches for CER by treating it as a sequence labeling task. We investigated transformer architecture for CER and, compared it with ResNet-34 and BiLSTM architectures in both contextual and context-less scenarios using IEMOCAP corpus. Based on the inner workings of the self-attention mechanism, we proposed DiverseCatAugment (DCA), an augmentation scheme, which improved the transformer model performance by an absolute 3.3% micro-f1 on conversations and 3.6% on isolated utterances. We further enhanced the performance by introducing an interlocutor-aware transformer model where we learn a dictionary of interlocutor index embeddings to exploit diarized conversations.
翻译:语音感知是承认演讲者情绪状态的任务。 虽然目前大多数方法侧重于从孤立的言语中推断情感,但我们认为这不足以实现谈话情绪识别(CER),涉及在谈话中识别情感。 在这项工作中,我们提出一些CER的方法,将它作为顺序标签任务处理。我们研究了CER的变压器结构,并将它与ResNet-34和BILSTM结构在背景和不切实际的情景下使用IMOCAP Camp进行对比。 根据自我感知机制的内部工作,我们提议了多功能搜索(DCA)计划,即增强功能计划,通过绝对3.3%的微宽频1和3.6%的孤立语句来改进变压器模型的性能。我们进一步提升了该功能,我们采用了一个对话感知变压器模型,在其中我们学习了一种对话索引嵌入字典,以利用二极分化的对话。