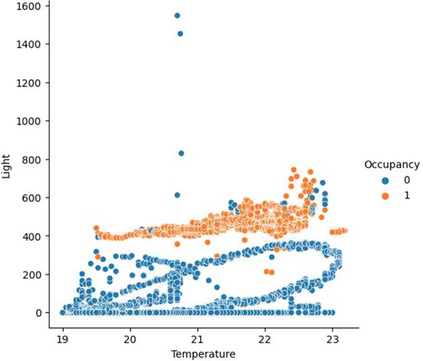
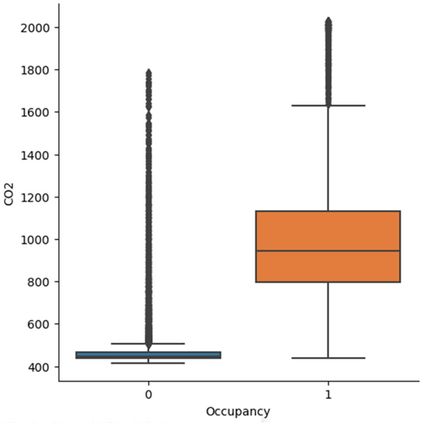
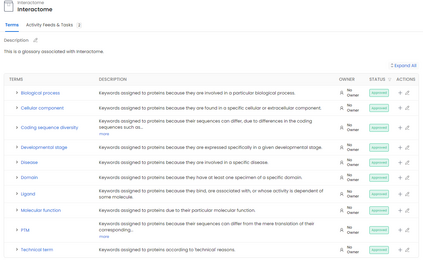
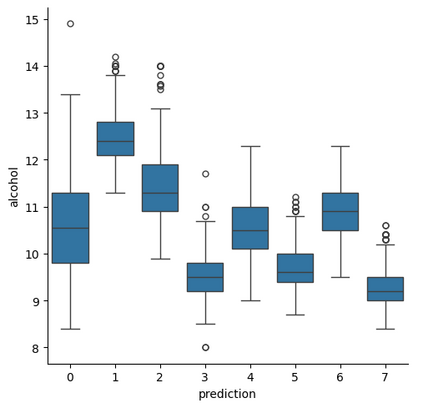
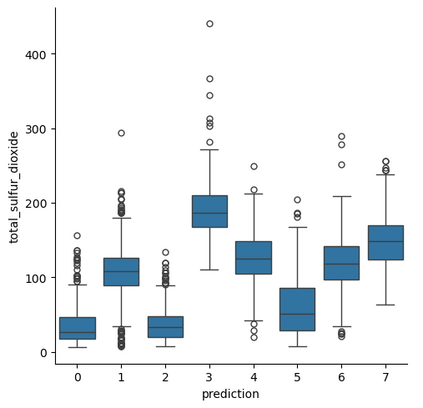
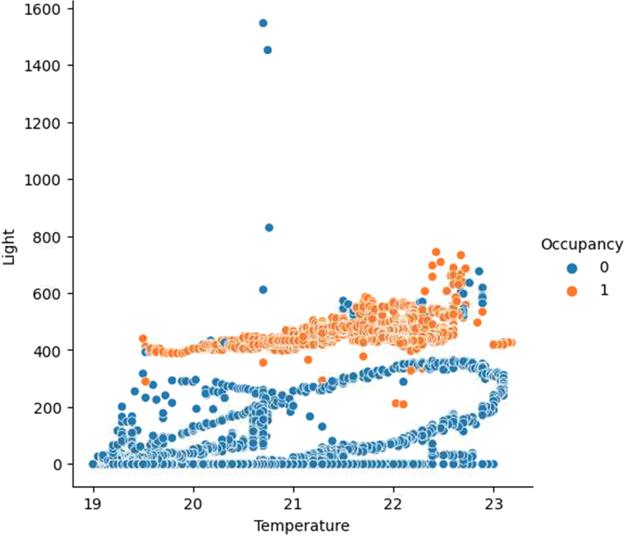
With the recent growth of Deep Learning for AI, there is a need for tools to meet the demand of data flowing into those models. In some cases, source data may exist in multiple formats, and therefore the source data must be investigated and properly engineered for a Machine Learning model or graph database. Overhead and lack of scalability with existing workflows limit integration within a larger processing pipeline such as Apache Airflow, driving the need for a robust, extensible, and lightweight tool to preprocess arbitrary datasets that scales with data type and size. To address this, we present Machine Learning Preprocessing and Exploratory Data Analysis, MLPrE, in which SparkDataFrames were utilized to hold data during processing and ensure scalability. A generalizable JSON input file format was utilized to describe stepwise changes to that DataFrame. Stages were implemented for input and output, filtering, basic statistics, feature engineering, and exploratory data analysis. A total of 69 stages were implemented into MLPrE, of which we highlight and demonstrate key stages using six diverse datasets. We further highlight MLPrE's ability to independently process multiple fields in flat files and recombine them, otherwise requiring an additional pipeline, using a UniProt glossary term dataset. Building on this advantage, we demonstrated the clustering stage with available wine quality data. Lastly, we demonstrate the preparation of data for a graph database in the final stages of MLPrE using phosphosite kinase data. Overall, our MLPrE tool offers a generalizable and scalable tool for preprocessing and early data analysis, filling a critical need for such a tool given the ever expanding use of machine learning. This tool serves to accelerate and simplify early stage development in larger workflows.
翻译:暂无翻译