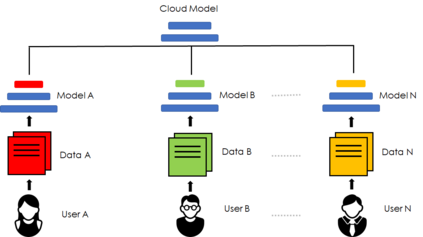
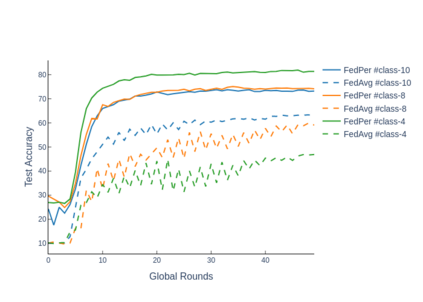
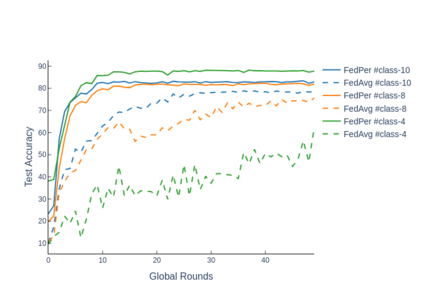
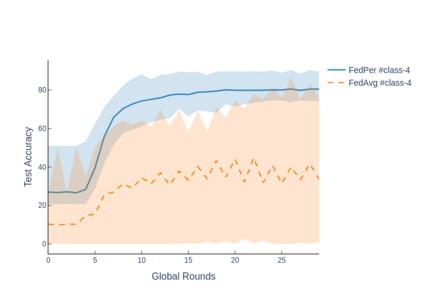
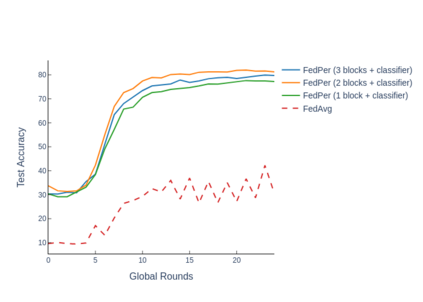
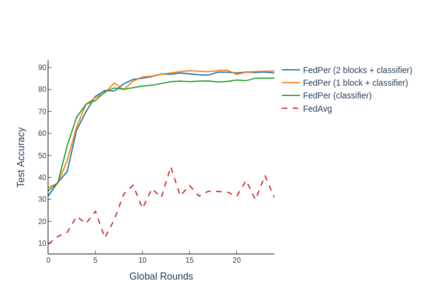
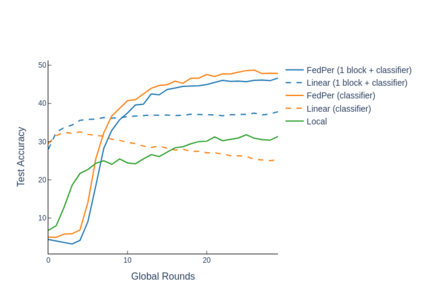
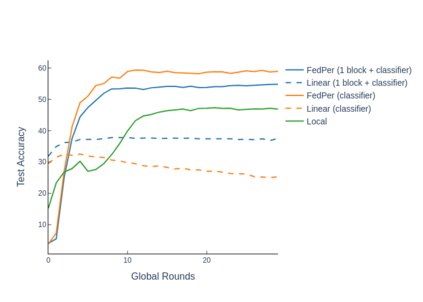
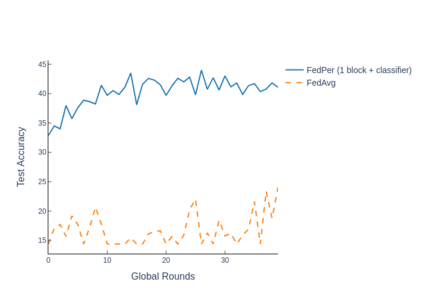
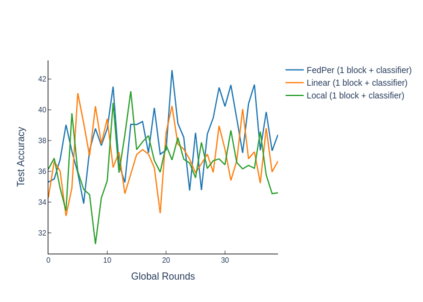
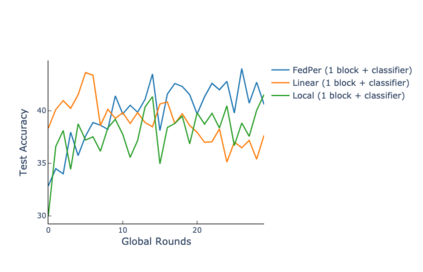
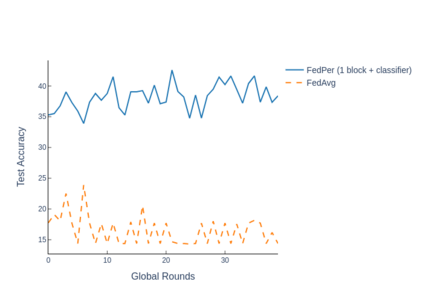
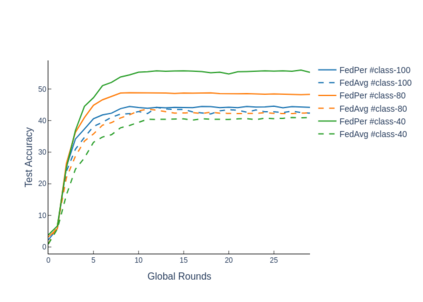
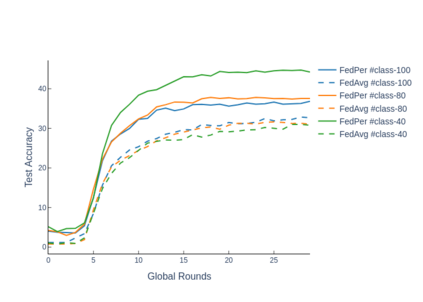
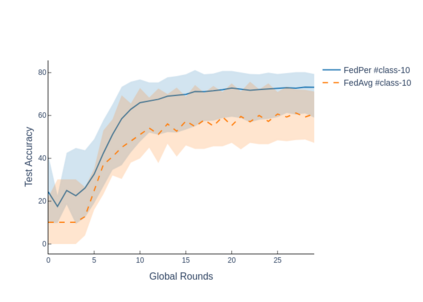
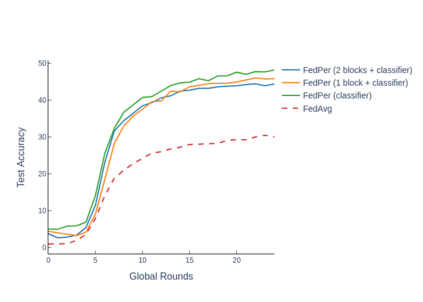
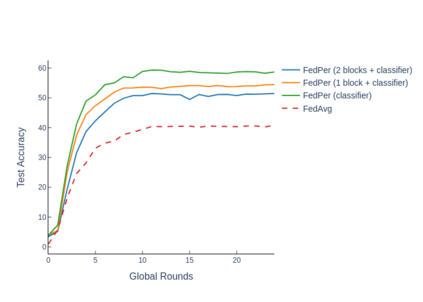
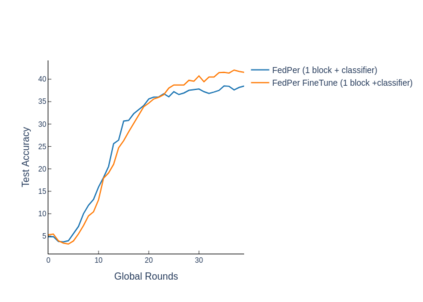
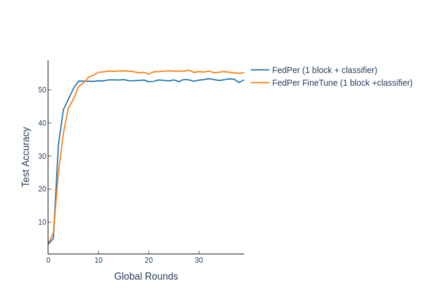
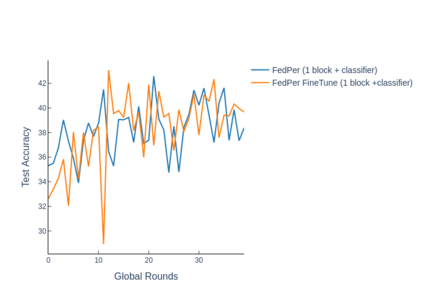
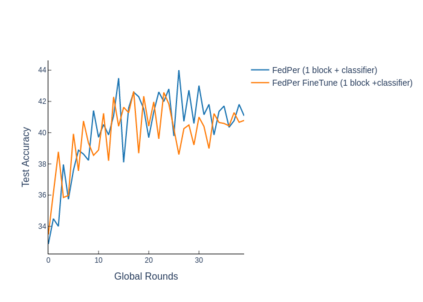
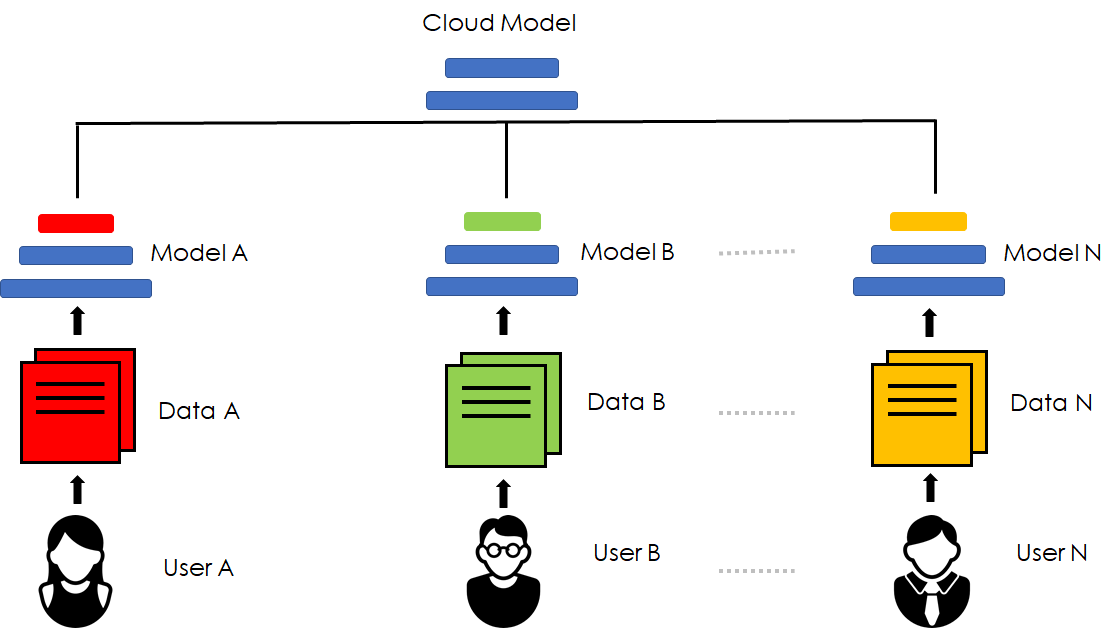
The emerging paradigm of federated learning strives to enable collaborative training of machine learning models on the network edge without centrally aggregating raw data and hence, improving data privacy. This sharply deviates from traditional machine learning and necessitates the design of algorithms robust to various sources of heterogeneity. Specifically, statistical heterogeneity of data across user devices can severely degrade the performance of standard federated averaging for traditional machine learning applications like personalization with deep learning. This paper pro-posesFedPer, a base + personalization layer approach for federated training of deep feedforward neural networks, which can combat the ill-effects of statistical heterogeneity. We demonstrate effectiveness ofFedPerfor non-identical data partitions ofCIFARdatasetsand on a personalized image aesthetics dataset from Flickr.
翻译:新兴的联邦学习模式力求在不集中汇集原始数据的情况下,在网络边缘对机器学习模式进行协作培训,从而改善数据隐私。这与传统的机器学习大相径庭,需要设计强有力的算法以适应各种异质性来源。具体地说,跨用户设备的统计数据差异性可以严重降低传统机器学习应用的标准联邦平均绩效,如通过深层次学习实现个性化。本文的辅助目标FedPer,这是对深厚饲料神经网络进行联合培训的基础+个性化层次方法,可以消除统计异质的不良效应。我们展示了CIFAR数据集和来自Flickr的个性化图像美学数据集的FedPerfor非同式数据分割法的有效性。