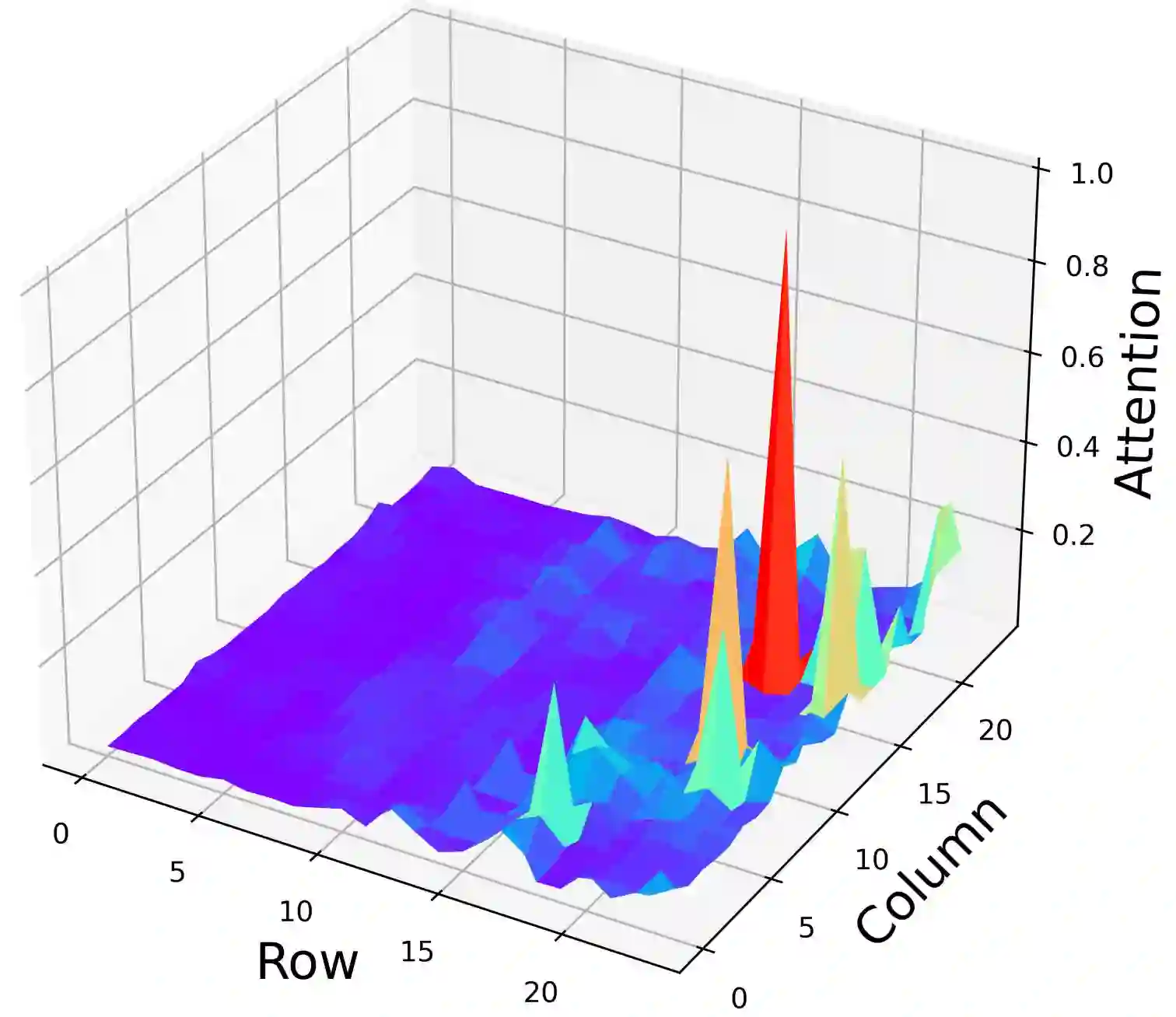
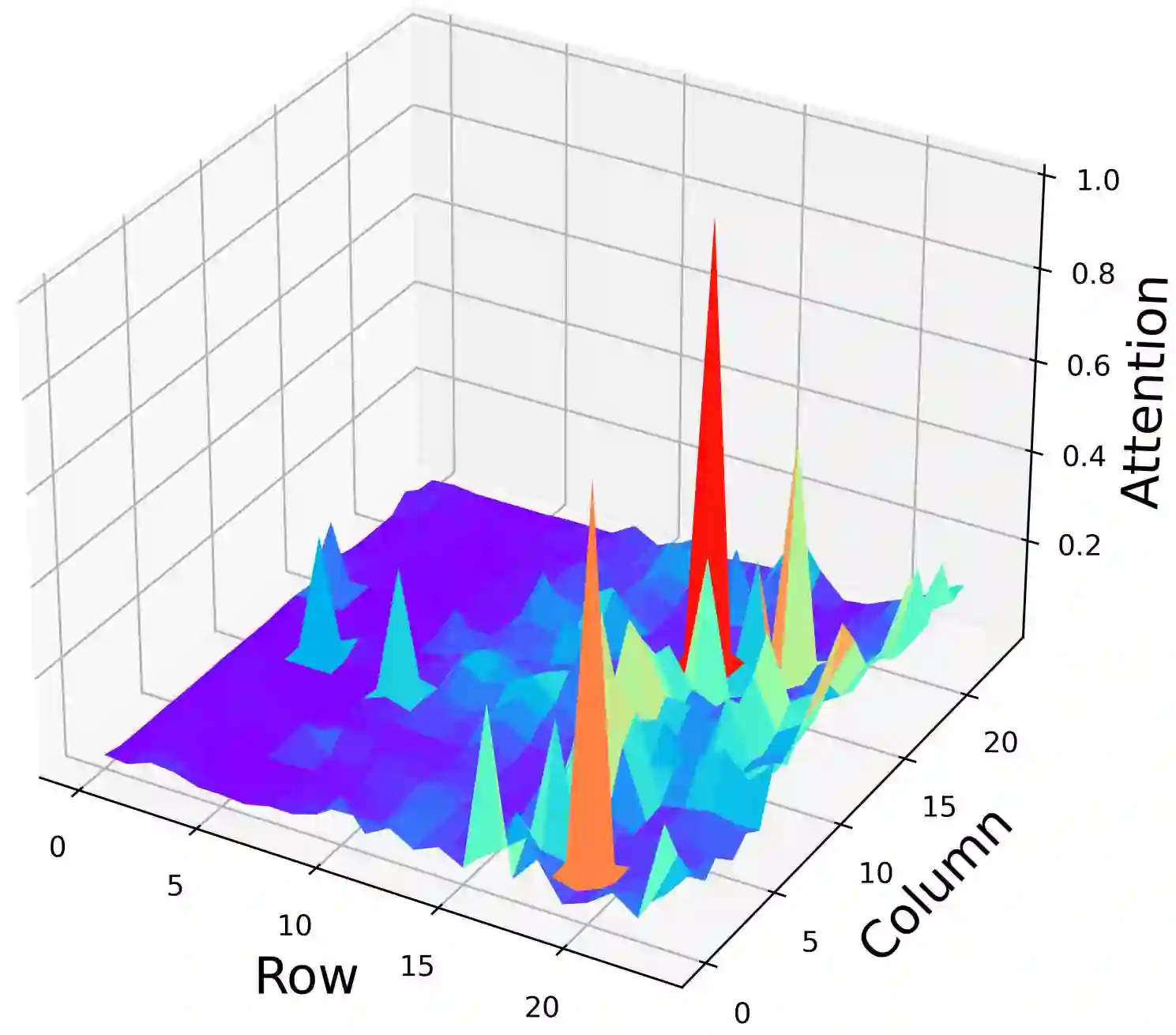
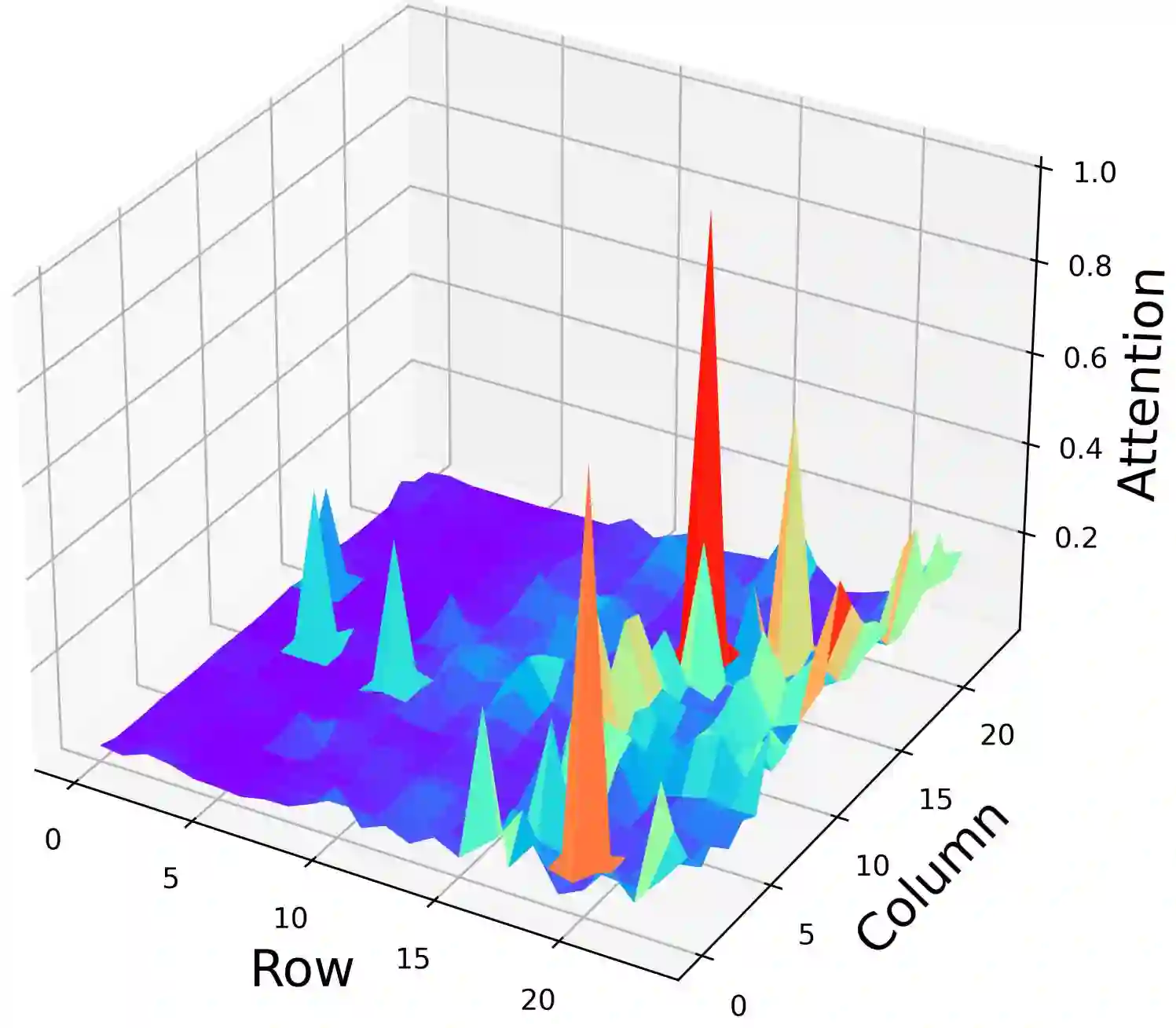
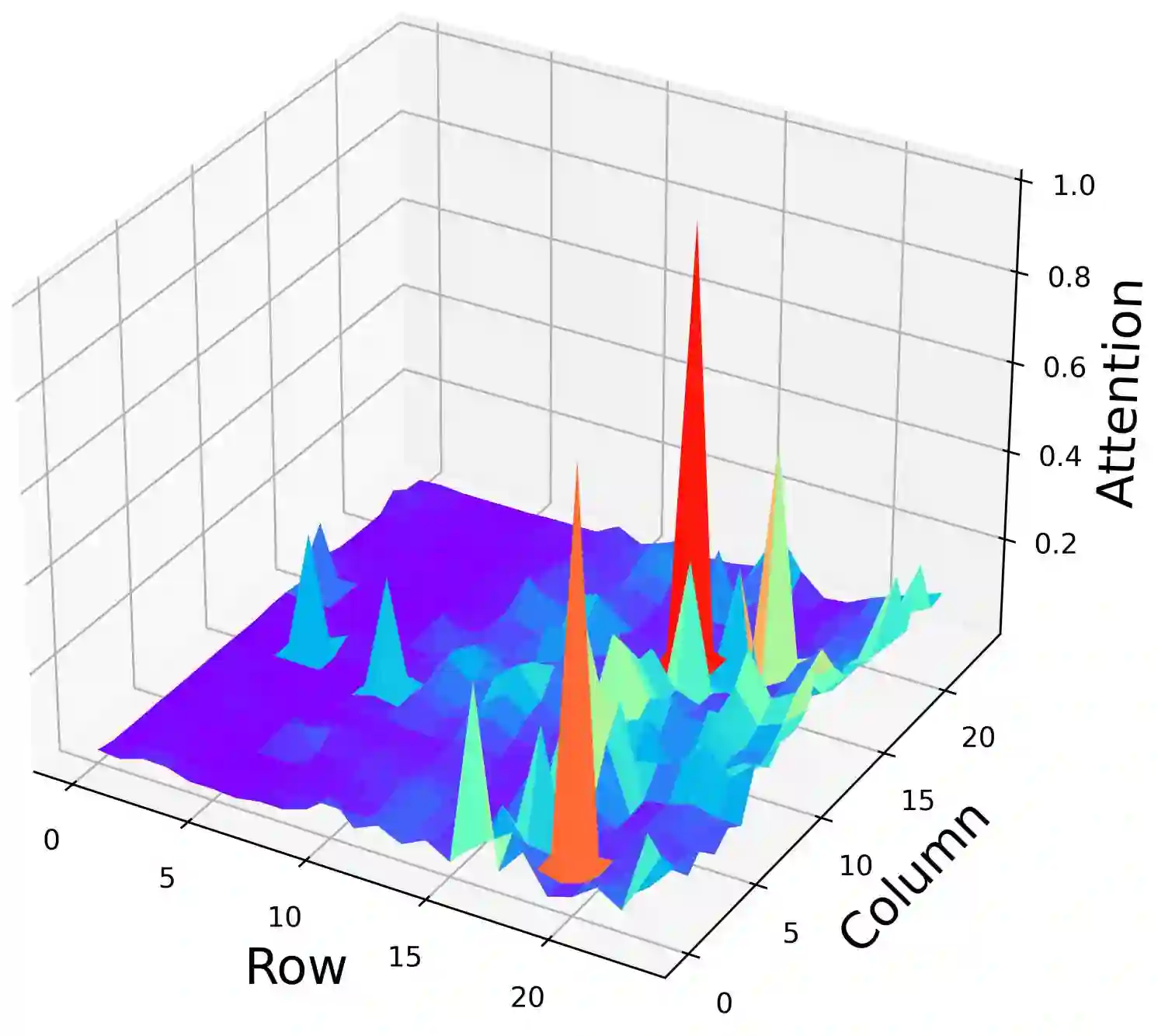
Despite their great success across various multimodal tasks, Large Vision-Language Models (LVLMs) are facing a prevalent problem with object hallucinations, where the generated textual responses are inconsistent with ground-truth objects in the given image. This paper investigates various LVLMs and pinpoints attention deficiency toward discriminative local image features as one root cause of object hallucinations. Specifically, LVLMs predominantly attend to prompt-independent global image features, while failing to capture prompt-relevant local features, consequently undermining the visual grounding capacity of LVLMs and leading to hallucinations. To this end, we propose Assembly of Global and Local Attention (AGLA), a training-free and plug-and-play approach that mitigates object hallucinations by exploring an ensemble of global features for response generation and local features for visual discrimination simultaneously. Our approach exhibits an image-prompt matching scheme that captures prompt-relevant local features from images, leading to an augmented view of the input image where prompt-relevant content is reserved while irrelevant distractions are masked. With the augmented view, a calibrated decoding distribution can be derived by integrating generative global features from the original image and discriminative local features from the augmented image. Extensive experiments show that AGLA consistently mitigates object hallucinations and enhances general perception capability for LVLMs across various discriminative and generative benchmarks. Our code will be released at https://github.com/Lackel/AGLA.
翻译:暂无翻译