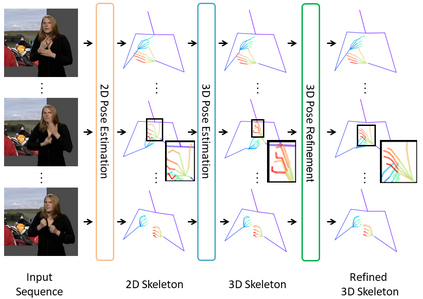
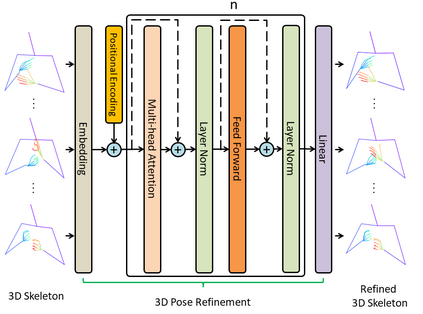
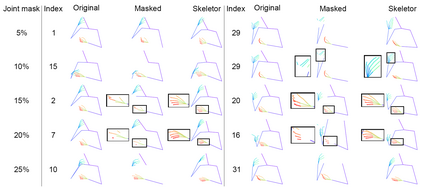
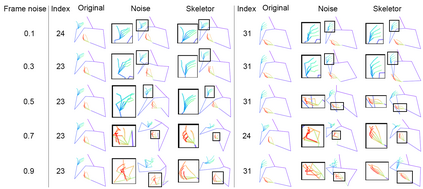
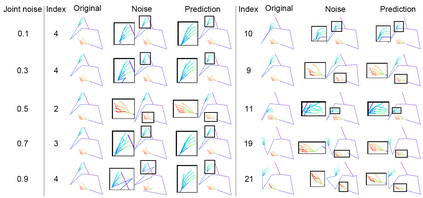
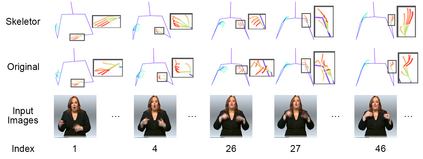
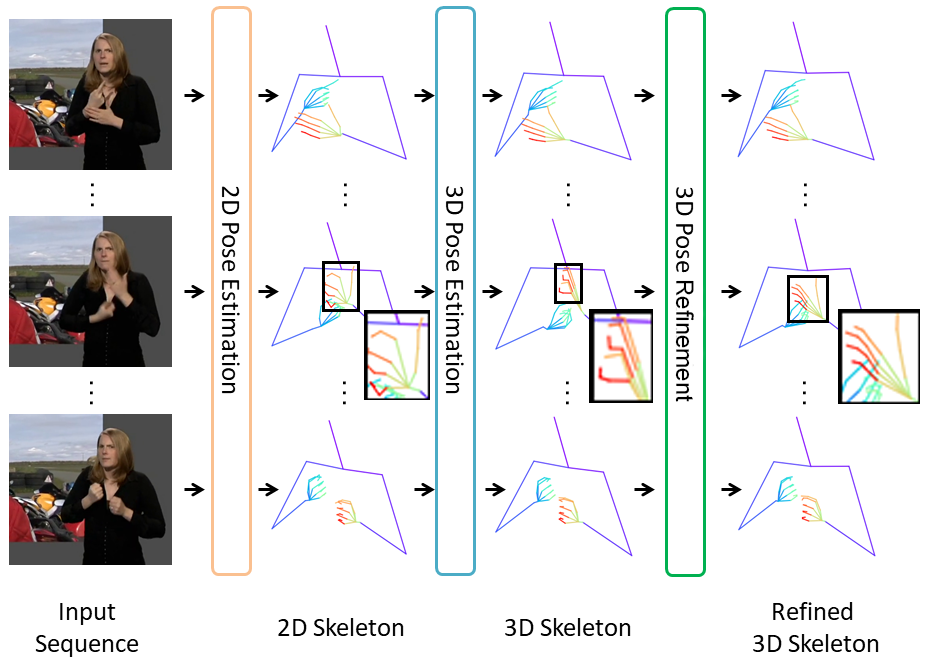
Predicting 3D human pose from a single monoscopic video can be highly challenging due to factors such as low resolution, motion blur and occlusion, in addition to the fundamental ambiguity in estimating 3D from 2D. Approaches that directly regress the 3D pose from independent images can be particularly susceptible to these factors and result in jitter, noise and/or inconsistencies in skeletal estimation. Much of which can be overcome if the temporal evolution of the scene and skeleton are taken into account. However, rather than tracking body parts and trying to temporally smooth them, we propose a novel transformer based network that can learn a distribution over both pose and motion in an unsupervised fashion. We call our approach Skeletor. Skeletor overcomes inaccuracies in detection and corrects partial or entire skeleton corruption. Skeletor uses strong priors learn from on 25 million frames to correct skeleton sequences smoothly and consistently. Skeletor can achieve this as it implicitly learns the spatio-temporal context of human motion via a transformer based neural network. Extensive experiments show that Skeletor achieves improved performance on 3D human pose estimation and further provides benefits for downstream tasks such as sign language translation.
翻译:单单单单相片的3D人造相的预测3D人造相,由于低分辨率、运动模糊和隐蔽等因素,预测3D人造相可能具有高度的挑战性。 此外,除了从 2D 中估算 3D 人造相的根本性模糊性之外,还存在根本性的模糊性。 直接从独立图像中反向3D 人造相的方法特别容易受这些因素的影响,并导致骨骼估计的紧张性、噪音和/或不一致性。如果将场景和骨架的时间变化考虑在内,其中的很大一部分是可以克服的。 但是,我们提议建立一个新型的基于变压机的变压器网络,能够以不受监督的方式对成形和运动进行分布。我们称之为Skeletor 的方法。Skeletor在检测和纠正部分或全部骨骼腐蚀方面克服了不准确性。Skeletor利用从2500万个框架学到的强力前科经验来纠正骨架序列的平稳和一贯性演变。 但是,Skeletor可以实现这一点,因为它暗地学习基于变压网络的人类运动的瞬间环境环境环境环境,我们提议。 广泛的实验显示,Skeletorssalalal latals ladess lavel lappss laus lapps pass pass pass