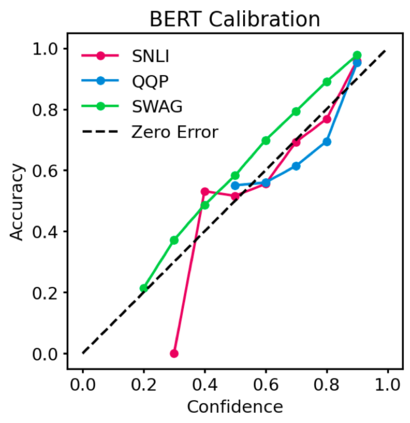
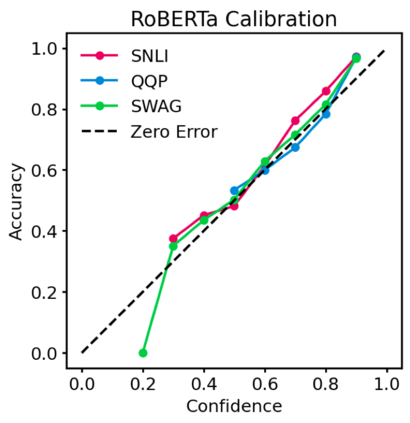
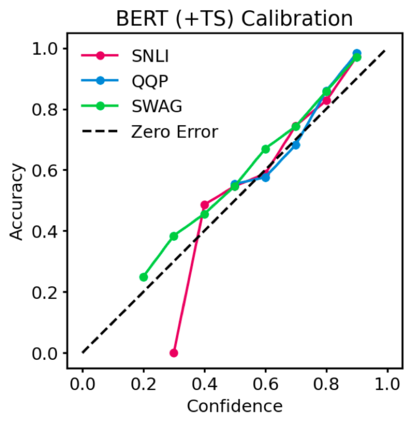
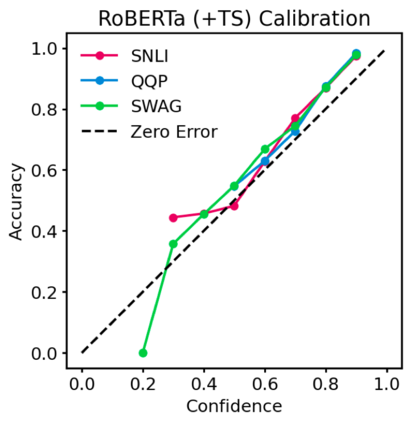
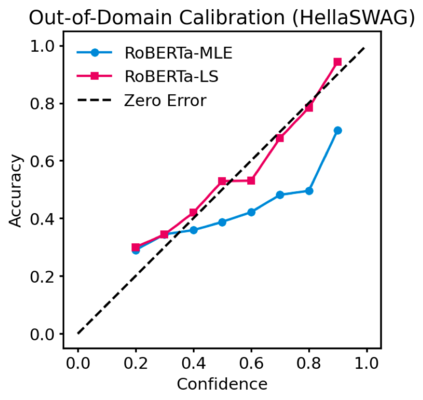
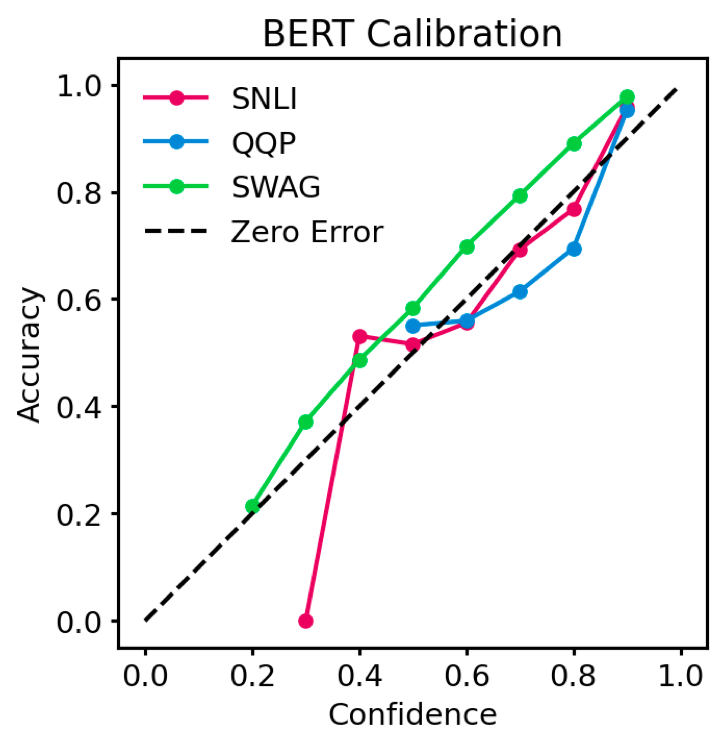
Pre-trained Transformers are now ubiquitous in natural language processing, but despite their high end-task performance, little is known empirically about whether they are calibrated. Specifically, do these models' posterior probabilities provide an accurate empirical measure of how likely the model is to be correct on a given example? We focus on BERT and RoBERTa in this work, and analyze their calibration across three tasks: natural language inference, paraphrase detection, and commonsense reasoning. For each task, we consider in-domain as well as challenging out-of-domain settings, where models face more examples they should be uncertain about. We show that: (1) when used out-of-the-box, pre-trained models are calibrated in-domain, and compared to baselines, their calibration error out-of-domain can be as much as 3.5x lower; (2) temperature scaling is effective at further reducing calibration error in-domain, and using label smoothing to deliberately increase empirical uncertainty helps calibrate posteriors out-of-domain.
翻译:受过培训的变异器在自然语言处理中现在无处不在,但尽管其最终任务性能很高,但很少从经验上知道它们是否被校准。具体地说,这些模型的后方概率是否提供了精确的实验性尺度,说明模型在某个特定例子中是否正确?我们在此工作中侧重于BERT和ROBERTA,并分析其分三项任务的校准:自然语言推论、参数探测和常识推理。对于每一项任务,我们考虑的是内部以及挑战外部设置,在哪些情况下模型应该面临更多不确定的例子。我们表明:(1) 当使用过的在框外的、预先训练的模型在外部校准时,与基线相比,它们的校准错误在外部可能低到3.5x;(2) 温度缩放对于进一步减少校准误差是有效的,并且使用标签来故意增加经验不确定性帮助校准外部的后部。