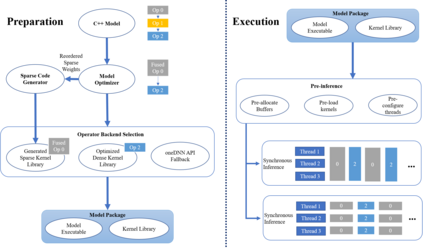
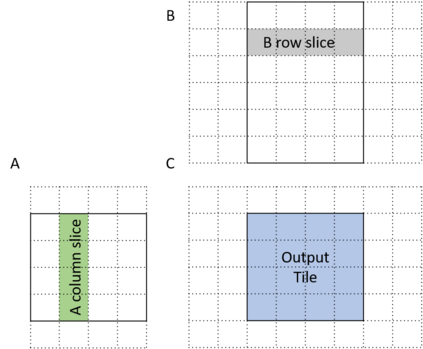
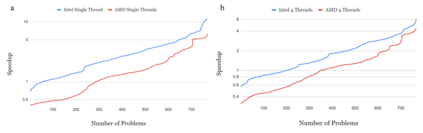
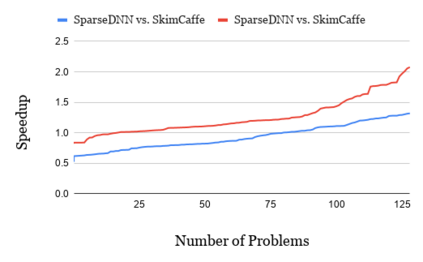
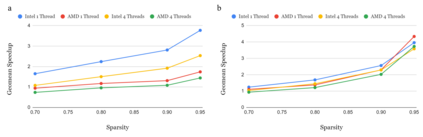
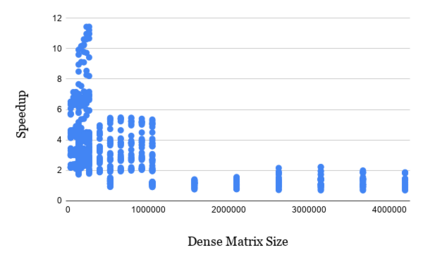
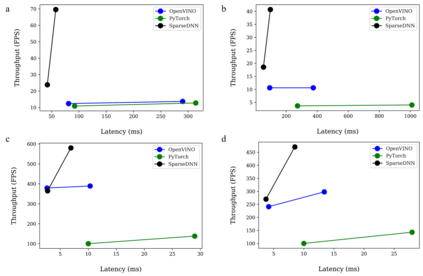
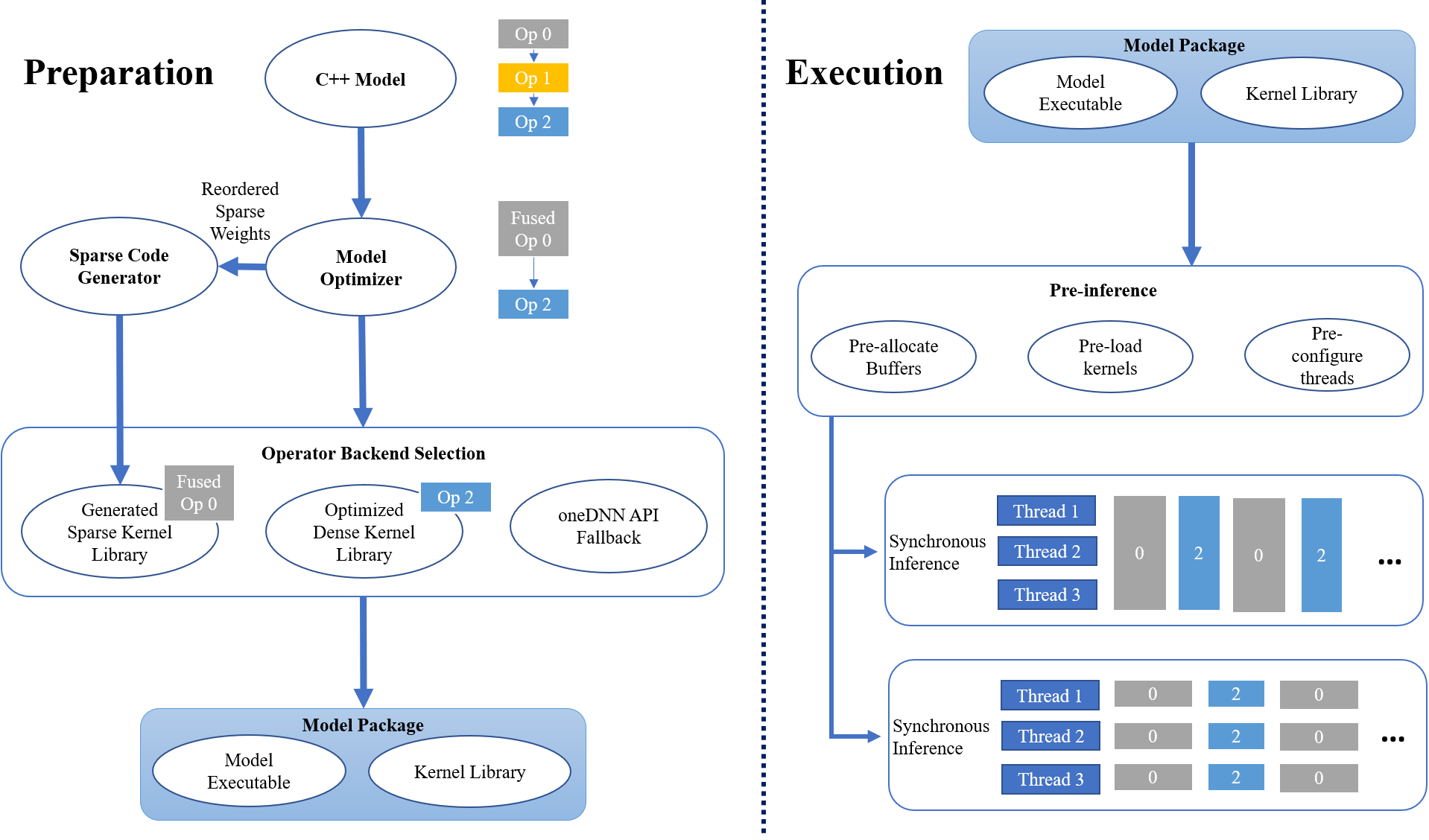
The last few years have seen gigantic leaps in algorithms and systems to support efficient deep learning inference. Pruning and quantization algorithms can now consistently compress neural networks by an order of magnitude. For a compressed neural network, a multitude of inference frameworks have been designed to maximize the performance of the target hardware. While we find mature support for quantized neural networks in production frameworks such as OpenVINO and MNN, support for pruned sparse neural networks is still lacking. To tackle this challenge, we present SparseDNN, a sparse deep learning inference engine targeting CPUs. We present both kernel-level optimizations with a sparse code generator to accelerate sparse operators and novel network-level optimizations catering to sparse networks. We show that our sparse code generator can achieve significant speedups over state-of-the-art sparse and dense libraries. On end-to-end benchmarks such as Huggingface pruneBERT, SparseDNN achieves up to 5x throughput improvement over dense inference with state-of-the-art OpenVINO. Open source library at: https://github.com/marsupialtail/sparsednn.
翻译:过去几年中,在支持高效深层学习推断的算法和系统中出现了巨大的飞跃。 普鲁宁和量化算法现在可以不断地按一个数量级压缩神经网络。 对于压缩神经网络来说,已经设计了多种推论框架来最大限度地提高目标硬件的性能。 虽然我们发现在OpenVINO和MNN等生产框架中对量化神经网络的成熟支持,但是对经处理的稀薄神经网络的支持仍然不足。为了应对这一挑战,我们提出了SprassDNNN,这是一个以CPU为对象的稀疏的深层次的深层推论引擎。我们提供了一个稀薄的代码生成器,以加速稀薄的操作器和新的网络级优化为稀薄的网络网络提供。我们展示了我们稀薄的代码生成器能够大大加速最先进的稀薄和密集的图书馆。 在Huggingface PruneBERT等终端到终端基准上, SprassDNNNN能够达到5x的增产值,超过高密度的州- art OpenVINO。 开放源库: http://gimarth.